Сайт не обходится в SEO Crawler — диагностика и решения
Если обход закончился с ошибкой, нашёл 0 страниц или остановился на первой — причина почти всегда на стороне целевого сайта: защита от ботов, robots.txt, SSL-проблемы, JS-рендер или перегрузка сервера. Ниже — последовательность, по которой стоит проверять: от простых проверок к сложным. По каждому пункту есть скриншоты интерфейса SEO Crawler, где вы увидите конкретные признаки проблемы.
nslookup. Если хотя бы одно — «не ок», причина найдена.Введите URL — краулер сделает один запрос и покажет реальный код ответа.
Полный обход каждой страницы с HTML-парсингом идёт по тем же правилам, что и эта разовая проверка — как работает краулер. Если даже одиночный запрос падает с ошибкой, обход тем более не пройдёт.
Сайт отдаёт 403 / 429 / 5xx
Эти коды ответа — главная категория ошибок обхода. В отчёте аудита статус виден в колонке «Код» в таблице всех страниц, а на дашборде обход со статусом «Ошибка» сразу бросается в глаза в списке задач.

403 Forbidden — сервер отклонил запрос
Сервер понял запрос, но отказался отвечать. Типичные причины:
- WAF / Cloudflare Bot Management. Распознал автоматический запрос и заблокировал.
- Авторизация. Страницы доступны только после логина — публичный обход невозможен.
- Геоблокировка. Сайт отдаёт контент только в определённых странах, наш сервер — в другой.
- Блокировка по IP. Наш диапазон попал в чёрный список (редко).
Решение: откройте URL в браузере без авторизации — если открывается, а у краулера 403, виноват WAF. Добавьте наш бот в whitelist (см. раздел ниже про Cloudflare). Если контент за логином — краулер не может туда попасть, это ограничение архитектуры.
429 Too Many Requests — слишком часто
Сайт временно ограничил доступ из-за частоты запросов. Краулер по умолчанию делает 1,5 запроса в секунду, но некоторые сайты рассчитаны на более редкие обращения. Решение: в расширенных настройках обхода понизьте скорость до 0,5 URL/сек. Если у сайта в robots.txt есть директива Crawl-delay, краулер автоматически её соблюдает.
500 / 502 / 503 / 504 — сервер упал
Эти коды означают проблему на стороне сайта, а не краулера. 500 — неперехваченная ошибка в коде приложения, 502 и 504 — проблема проксирования (чаще всего перегрузка), 503 — явное «сервис недоступен» или режим обслуживания. Решение: проверьте логи сервера, попробуйте обход в менее загруженное время (ночью). Если 503 возвращает Cloudflare — это тоже сигнал бот-защиты, читайте раздел про Cloudflare.
robots.txt блокирует наш User-Agent
Перед началом обхода краулер загружает /robots.txt и соблюдает директивы для User-agent: *. Если весь сайт закрыт директивой Disallow: /, вы получите 0 обойдённых страниц. Если закрыт конкретный раздел — краулер просто пропустит его.
Пример robots.txt, который закрывает весь сайт:
User-agent: *
Disallow: /А этот — закрывает только админку и не мешает обходу:
User-agent: *
Disallow: /admin/
Disallow: /api/
Crawl-delay: 2В отчёте причина пропуска URL видна в колонке «Robots» — там будет метка disallow для заблокированных страниц. Более подробно про директивы — в статье robots.txt и noindex.
Если сайт — ваш, а вам нужно проверить, что на нём происходит, несмотря на запреты: в расширенных настройках поставьте галку «Игнорировать robots.txt». Для чужих сайтов так делать не стоит — это нарушение договорённости между ботом и владельцем.
Cloudflare и другие bot-protection
Cloudflare, Akamai, Imperva, Sucuri и похожие WAF-сервисы по умолчанию включают защиту от ботов. Конкретные признаки того, что сайт под такой защитой:
- HTTP-код 403 или 503 на все страницы кроме главной.
- В заголовках ответа есть
Server: cloudflareилиcf-ray. - При ручном открытии появляется «Checking your browser before accessing…» или капча.
Решение — добавить наш краулер в whitelist. В Cloudflare:
- Откройте Security → WAF → Custom Rules → Create rule.
- Условие:
User AgentcontainsSEOCrawlerBot. - Действие: Skip → All remaining custom rules, Security Level, Managed Challenge.
- Deploy → запустите обход заново.
Альтернатива — whitelist по IP. Наш сервер имеет фиксированный IP; актуальное значение вы можете узнать, запустив виджет «Проверить URL нашим ботом» выше и посмотрев логи своего сервера — там появится запись с нашим User-Agent и IP. Либо напишите в поддержку, мы пришлём IP для whitelist.
Googlebot, чтобы «обмануть» Cloudflare. У Google есть публичный список IP-адресов Googlebot — WAF делает reverse DNS и отклоняет запросы с чужих IP. Используйте настоящий whitelist по нашему User-Agent или IP.SSL-ошибки: expired, self-signed, chain
Если у сайта проблемный HTTPS, краулер не установит соединение и отдаст ошибку «Не удалось проверить SSL-сертификат сайта». Три основных типа проблем:
- Expired. Сертификат просрочен. Проверьте дату через
curl -vI https://example.com 2>&1 | grep -i expireили на SSL Labs. - Self-signed. Самоподписанный сертификат без доверенного CA. Для публичных сайтов не подходит — ни один современный краулер и браузер его не примет без предупреждения.
- Неполная цепочка. Сервер отдаёт только leaf-сертификат без intermediate. Проверьте через SSL Labs — раздел «Chain issues».
Решение: выпустите новый сертификат через Let's Encrypt (бесплатно, автопродление) или купите у коммерческого CA. Ошибки цепочки обычно лечатся правильной конфигурацией Nginx/Apache — проверьте, что в конфиге указан ssl_certificate fullchain.pem, а не только cert.pem.
Редиректы на другой домен
Краулер автоматически следует за редиректами (301, 302, 307, 308). Если вы запустили обход http://example.com, а сервер отвечает 301 на https://www.example.com, краулер перейдёт по редиректу и начнёт обход с новой базы. Это нормальное поведение.
Проблемы возникают в двух случаях:
- Бесконечный редирект (redirect loop). Сервер зацикливает
/page→/page/→/page. Краулер прерывает соединение после 10 хопов и помечает URL ошибкой «Too many redirects». - Редирект за пределы домена. Если главная
example.comредиректит наexample.org, краулер не перейдёт — это другой домен, и обход завершится с 0 страниц.
Решение: проверьте настройки редиректов в Nginx / Apache / CMS. Убедитесь, что 301 всегда ведут на один и тот же целевой URL без циклов. Если сайт переехал на другой домен — запускайте обход сразу с нового адреса.
JavaScript-рендер: SPA и нет контента
SEO Crawler парсит только статический HTML, полученный от сервера. Если сайт построен на React, Vue, Angular, Svelte или другом SPA-фреймворке и рендерит контент в браузере — краулер увидит пустой HTML-каркас без текста и ссылок. В отчёте это выглядит так:
- Title и H1 пустые, хотя в браузере есть.
- Количество слов = 0 или 3–5 (только «Loading…» или такие же фразы).
- Внутренних ссылок 0, хотя в навигации десятки пунктов.
- HTTP-статус при этом 200 — всё «успешно».
Решение — серверный рендер. Три варианта:
- SSR (Server-Side Rendering). Next.js, Nuxt, SvelteKit рендерят страницу на сервере и отдают боту готовый HTML. Лучший вариант по производительности и SEO.
- SSG (Static Site Generation). Gatsby, Astro, Hugo собирают статические HTML-файлы на этапе билда. Идеально для сайтов без динамического контента.
- Prerender для ботов. Сервисы вроде Prerender.io делают серверный рендер только для краулеров по User-Agent. Компромисс для готовых SPA, которые не хочется переписывать.
Почему это важно не только для нас: Google умеет рендерить JS, но делает это во втором проходе индексации (через дни или недели после первого). Яндекс JS не рендерит вовсе. Любая прослойка SSR — это ускорение индексации в разы.
Сайт слишком медленный: таймауты
Краулер ждёт ответа на каждый запрос максимум 10 секунд. Если сервер не уложился, URL помечается ошибкой «Сервер не ответил вовремя (таймаут)», и краулер переходит к следующему адресу. Обход при этом не останавливается — просто в колонке «Ошибка» накапливаются таймауты.
Причины медленных ответов:
- Тяжёлые SQL-запросы на каждой странице (нет кеширования).
- Медленный shared-хостинг с перегруженными соседями.
- Большой HTML (5–10 МБ) — скачивается долго. Краулер режет страницы больше 5 МБ.
- Удалённые API-запросы в серверном коде, которые блокируют ответ.
Решение: проверьте TTFB на главных страницах — он не должен стабильно превышать 2–3 секунды. Если превышает — нужна оптимизация сервера: кеш, индексы в БД, CDN. Подробнее о метрике TTFB и том, как её интерпретировать — в статье TTFB и скорость.
Если таймауты на отдельных страницах, а основная часть сайта летает, запустите обход ночью — когда нагрузка меньше. И снизьте скорость до 0,5 RPS, чтобы дать серверу время дышать.
Контент есть, а обход не идёт
Бывает ситуация: главная страница открылась, вернула 200, контент на месте — но краулер прошёл всего 1–2 URL и остановился. Три типичные причины:
Лимит глубины или страниц
Проверьте расширенные настройки обхода. Если там стоит «Макс. глубина» = 1, краулер обойдёт только стартовую страницу без переходов по ссылкам. «Макс. URL» = 1 — то же самое по числу.
Нет внутренних ссылок с главной
Если ваша главная — лендинг без навигации в подвале (или вся навигация — кнопки, которые не являются <a>), краулер просто не найдёт, куда идти дальше. Добавьте sitemap в меню и подвал или переведите режим на «Список URL» и вставьте конкретные адреса.
Orphan-страницы
Страницы без единой входящей ссылки (так называемые «сироты») краулер не обнаружит в принципе. Если вы знаете, что они должны быть — вы либо их линкуете из основной навигации, либо проверяете их отдельно через режим «Список URL».
Диагностика по коду ответа
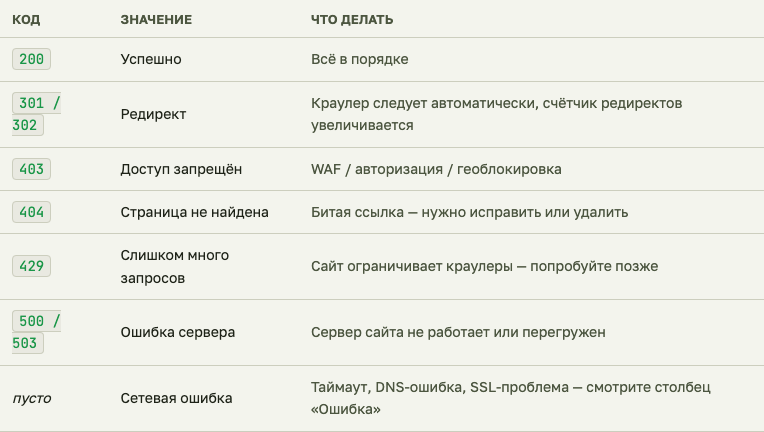
| Код | Значение | Что делать |
|---|---|---|
200 |
Успешно | Всё в порядке, страница проанализирована |
301 / 302 |
Редирект | Краулер следует автоматически, счётчик редиректов увеличивается |
403 |
Доступ запрещён | WAF / авторизация / геоблокировка — добавьте в whitelist |
404 |
Страница не найдена | Битая ссылка — нужно исправить или удалить |
429 |
Слишком много запросов | Понизьте скорость в расширенных настройках |
500 / 503 |
Ошибка сервера | Сервер сайта не работает или перегружен, попробуйте позже |
| пусто | Сетевая ошибка | Таймаут, DNS-ошибка, SSL-проблема — смотрите столбец «Ошибка» |
Ограничения краулера
- JavaScript не выполняется. Только статический HTML-ответ сервера.
- Авторизация не поддерживается. Закрытые логином страницы не обходятся.
- Только HTTP и HTTPS. Схемы
ftp://,file://,javascript:игнорируются. - Максимальный размер страницы: 5 МБ. Более крупный HTML не скачивается.
- Таймаут: 10 секунд на каждую страницу.
- Только внутренние ссылки. Поддомены (blog.example.com) считаются отдельным сайтом.
- Лимит страниц по тарифу: Free — 50, Pro/Trial — 500.
- Локальные адреса заблокированы (SSRF-защита): localhost, 127.x.x.x, 192.168.x.x, 10.x.x.x.
Частые вопросы
Какой User-Agent у краулера SEO Crawler?
По умолчанию краулер представляется как SEOCrawlerBot/1.0 (+https://seo-crawler.ru). В расширенных настройках обхода можно выбрать Chrome, Googlebot или Bingbot — полезно для проверки того, как сайт отвечает разным ботам. Наш User-Agent стабилен: вы можете использовать его в правилах WAF и allowlist для пропуска через защиту.
С какого IP стучится краулер?
Обходы идут с сервера seo-crawler.ru — фиксированный IP-адрес, который легко добавить в whitelist Cloudflare или другого WAF. Актуальный IP можно узнать, запустив разовую проверку URL прямо в браузере — в логах вашего сервера появится запись с нашим User-Agent и IP. Либо напишите в поддержку — мы вышлем актуальный IP для whitelist.
Почему стартовая страница отдаёт 200, а остальные 403?
Чаще всего это Cloudflare Bot Fight Mode или похожая защита: первый запрос проходит, а последующие бот определяется по паттерну и блокируется. Решение — добавить наш User-Agent или IP в whitelist правилами WAF. Второй вариант — понизить скорость в расширенных настройках до 0,5 RPS, иногда это помогает обойти эвристику.
Выполняет ли SEO Crawler JavaScript?
Нет. Краулер работает с исходным HTML, который возвращает сервер — как Googlebot на первом проходе. Если ваш сайт — SPA на React, Vue или Angular и рендерит контент в браузере, краулер увидит пустой HTML с минимальным каркасом. Решение: Server-Side Rendering (SSR), Static Site Generation (SSG) или prerender для ботов.
Обходит ли краулер по sitemap.xml?
Нет, основной режим обхода — BFS по внутренним ссылкам с указанного стартового URL. Если ваши страницы не имеют внутренних ссылок (orphan pages), они не попадут в отчёт. Как workaround — используйте режим «Список URL» и вставьте туда URL из sitemap.xml. Краулер проверит именно эти страницы без обхода по ссылкам.
Как добавить SEO Crawler в whitelist Cloudflare?
В Cloudflare откройте Security → WAF → Custom Rules. Создайте правило: if User-Agent contains «SEOCrawlerBot» then Skip (All remaining custom rules, Security Level, Managed Challenge). Либо по IP: if IP Source Address equals «наш IP» then Skip. После создания правила запустите обход заново — страницы должны начать отдавать 200.
Почему обход обрывается на середине?
Три основные причины: достигнут лимит «Макс. URL» (посмотрите счётчик URL — если он равен лимиту, обход завершён штатно); сервер начал отвечать 429 (слишком частые запросы) — понизьте скорость в настройках; сервер начал падать в 5xx (перегрузка) — попробуйте обход в нерабочее время или на более медленной скорости.
Есть ли у краулера лимит страниц за один обход?
Да. На тарифе Free — до 50 страниц за обход, на Pro и Trial — до 500. Лимит задаётся в поле «Макс. URL» при создании обхода. Если сайт больше — увеличьте тариф или используйте паттерны «Парсить только» в расширенных настройках, чтобы ограничить обход конкретным разделом.
Что делать, если ни одна из причин не подходит?
Воспользуйтесь виджетом «Проверить URL нашим ботом» в верхней части страницы — он делает разовый запрос и показывает реальный код ответа и текст ошибки. Если и это не прояснило ситуацию — нажмите «Фидбэк» в шапке и пришлите нам URL сайта вместе с описанием того, что вы видите в отчёте. Мы посмотрим логи на сервере и подскажем, что происходит.
Краулер не обходит HTTP-сайт — что делать?
Если ваш сайт доступен только по HTTP — явно укажите http:// в URL при запуске обхода. По умолчанию при отсутствии схемы подставляется https://, поэтому обход упадёт с ошибкой подключения. Рекомендуем всё-таки настроить HTTPS — это влияет на ранжирование и доверие пользователей. Подробнее — в статье TTFB и скорость.