Как краулер обходит ваш сайт и что собирает
SEO Crawler проводит технический аудит сайта: открывает стартовый URL, обходит внутренние страницы по ссылкам и собирает со всех найденных страниц метаданные — title, H1, description, canonical, Open Graph, HTTP-статусы, TTFB, ссылки, изображения без alt и ещё десяток параметров. Всё это попадает в отчёт, где вы увидите, какие страницы проиндексируются хорошо, а какие нужно править.
Эта страница — продуктовая документация: как запустить обход в интерфейсе, что происходит под капотом, какие ограничения и как настроить повторные обходы по расписанию. Для общей теории краулинга посмотрите чек-лист SEO-аудита сайта: 20 пунктов для новичков — там разобран порядок проверок и приоритеты.
Начало обхода: как запустить
Откройте /dashboard — первый блок «Новый парсинг» уже развёрнут по умолчанию. Для запуска достаточно трёх действий: вставить URL сайта, задать «Макс. URL» (лимит страниц за обход) и нажать «Запустить».

https://example.com, а не example.com. Если оставите без схемы — краулер подставит https:// автоматически, но если у вас только HTTP — обход упадёт с ошибкой подключения.Поле «Регулярность» переключает обход между разовым и повторяющимся (еженедельно / ежемесячно). Расписание создаёт scheduler-задачу, которая сама запускает обход с теми же настройками, которые вы указали при создании. Старые расписания на тот же домен автоматически деактивируются — одновременно на сайте может быть только одно активное расписание.
Кроме режима «Краулер» есть режим «Список URL» — переключатель справа в шапке блока. В этом режиме вы вставляете список конкретных страниц (по одной на строку, до 500 штук) и краулер проверит именно их, не переходя по ссылкам. Полезно, если нужно проверить состояние конкретного набора страниц — например, каталог после миграции.
Принцип BFS: обход в ширину
Краулер использует классический алгоритм BFS (breadth-first search, обход в ширину). В двух словах: сначала обходятся все страницы, до которых можно дойти за один клик со стартовой, затем за два клика, за три и так далее. Альтернатива — DFS (depth-first) — забуривается вглубь одной ветки, и при ограниченном лимите вы рискуете получить отчёт по одному забытому разделу сайта вместо общей картины.
BFS подходит для SEO-аудита по трём причинам:
- Популярные страницы обходятся первыми. Главная, каталог, основные категории всегда ближе всего к корню — именно они собирают больше всего трафика, их важно проверить в первую очередь.
- Прогнозируемые результаты. При лимите в 50 страниц вы получите 50 наиболее важных URL, а не 50 карточек товаров из одного раздела.
- Глубина коррелирует с приоритетом. Чем дальше страница от главной, тем меньше внутренних ссылок на неё, тем ниже её приоритет для поисковика. Поэтому «глубина» в отчёте — полезная метрика сама по себе.
Пошагово алгоритм выглядит так:
- Краулер загружает стартовый URL.
- Из HTML извлекаются все ссылки
<a href="...">. - Фильтруются ссылки — остаются только внутренние (тот же домен, без поддоменов), без
rel="nofollow", не запрещённые в robots.txt. - Новые ссылки добавляются в конец очереди.
- Из начала очереди берётся следующий URL, процесс повторяется.
- Обход заканчивается, когда достигнут лимит «Макс. URL», закончились ссылки или вы нажали «Стоп».
Прогресс обхода виден в таблице «Задачи» — статус «Выполняется» и растущий счётчик URL. По умолчанию задачи сгруппированы по домену: если вы уже обходили этот сайт, новая попытка добавится в общую группу, и кликом по строке вы раскроете историю всех обходов.
Что собирается на каждой странице
Для каждого URL краулер сохраняет набор данных, на основе которых потом считается Health Score и формируются карточки проблем в отчёте:
| Параметр | Что именно сохраняется |
|---|---|
| HTTP-статус | Код ответа сервера (200, 301, 404, 5xx) + цепочка редиректов до финального URL |
| Title | Текст тега <title>, длина в символах, количество title на странице |
| Meta description | Текст <meta name="description"> и длина |
| H1 и иерархия | Первый H1, количество H1 на странице, список остальных заголовков H2–H6 |
| Canonical | Значение <link rel="canonical">, проверка соответствия текущему URL |
| Meta robots | Директивы index/noindex, follow/nofollow из <meta name="robots"> и заголовка X-Robots-Tag |
| Open Graph | og:title, og:description, og:image, og:type |
| Lang | Значение атрибута lang в <html> |
| Изображения | Общее количество <img> и сколько из них без атрибута alt |
| Внутренние / внешние ссылки | Число ссылок каждого типа, список внутренних ссылок для построения графа |
| Контент | Количество слов в видимом тексте, базовый signature для поиска дублей |
| TTFB | Время до первого байта ответа (мс) — ключевая метрика скорости сервера |
| Размер и редиректы | Размер HTML в байтах, количество редиректов в цепочке |
| Глубина | Кратчайшее число кликов от стартового URL |
Все эти данные попадают в отчёт аудита. Сводку по обходу вы увидите сразу в верхней части страницы — количество проверенных URL, Health Score, число ошибок и предупреждений:
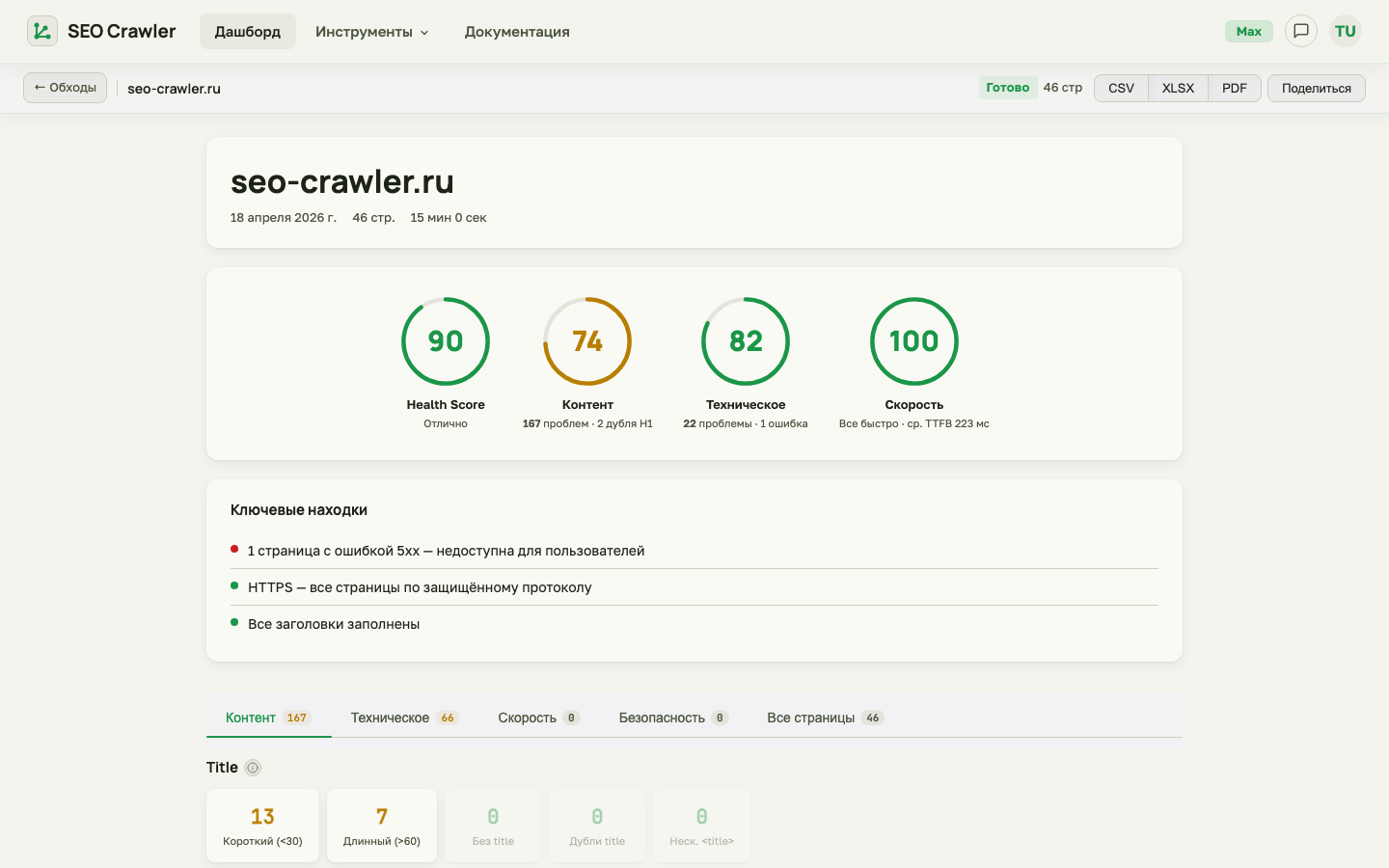
Для точечных проверок отдельных URL без полного обхода есть онлайн-инструменты — проверка мета-тегов, robots.txt, SSL, TTFB, битых ссылок и hreflang. Они работают без авторизации и не расходуют лимит обходов.
Лимиты обхода и связь с тарифом
В расширенных настройках (ссылка «Расширенные настройки» под основной формой) можно тонко контролировать обход — скорость, глубину, включающие и исключающие шаблоны, User-Agent и поведение относительно robots.txt.
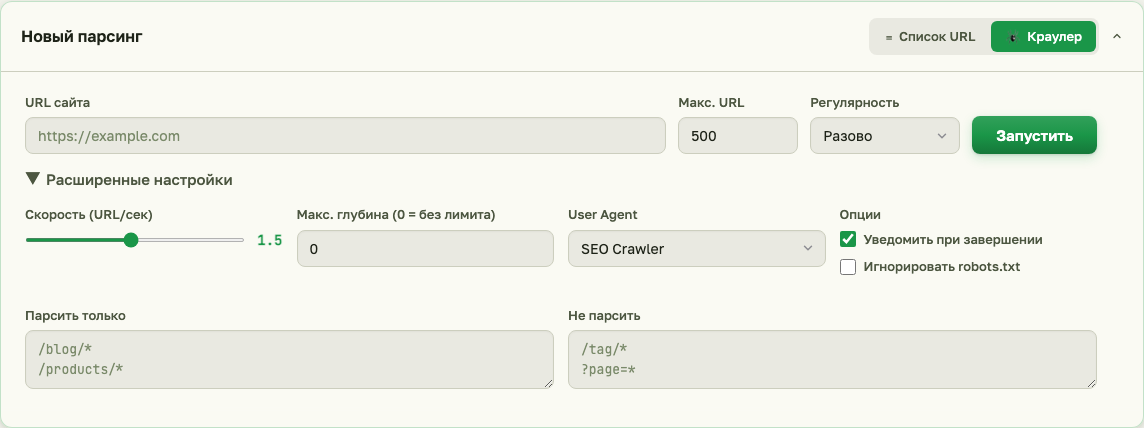
- Макс. URL — главный лимит. Free: до 50, Pro/Trial: до 500. По исчерпании краулер останавливается и фиксирует обход как завершённый.
- Скорость (URL/сек) — от 0,1 до 3 запросов в секунду. Низкое значение — для shared-хостинга и слабых серверов, высокое — для крупных проектов.
- Макс. глубина — 0 значит «без лимита», 1 — только стартовая страница, 2 — стартовая + прямые ссылки с неё, и так далее.
- Таймаут на страницу — 10 секунд. Если сервер не ответил — URL помечается ошибкой, обход продолжается.
- Максимальный размер страницы — 5 МБ. Большие HTML не скачиваются.
- Только HTTP/HTTPS. Схемы
ftp://,file://,javascript:игнорируются.
Месячная квота обходов считается по числу запусков, а не по числу страниц: один обход на 500 страниц = одна единица квоты. Подробнее о тарифах — в разделе Free, Pro и Trial или на странице тарифов.
localhost, приватные диапазоны (10.x, 192.168.x, 172.16–31.x) и AWS/GCP metadata. Это защита от SSRF-атак. Для проверки сайтов в разработке используйте публичный туннель вроде ngrok.robots.txt и служебные файлы
Перед началом обхода краулер запрашивает /robots.txt и парсит группу директив для User-agent: *. Если путь запрещён в Disallow — URL пропускается. Если встретится директива Crawl-delay, она применится к нашим запросам.
Если robots.txt недоступен (5xx, таймаут, 404) — краулер работает по принципу fail-open: считает, что разрешено всё. Это стандартное поведение, рекомендованное Google: мы не блокируем обход сайта из-за временных проблем с одним служебным файлом.
В расширенных настройках есть опция «Игнорировать robots.txt» — включайте её только на своих сайтах, когда хотите проверить, что там на самом деле. Для публичного аудита, где вы не владеете сайтом, эта галка должна быть снята. Подробнее — в статье robots.txt и noindex.
Канонизация URL: краулер приводит ссылки к виду, совместимому с поисковой индексацией — нормализует trailing slash, убирает якоря (#section), не переходит по mailto:, tel: и javascript:. При этом он различает http:// и https://, а также с www и без: если главная делает 301-редирект на www-версию, обход продолжится с новой базы.
Сохранение результатов и повторные обходы
После завершения обхода задача остаётся в истории. На дашборде задачи сгруппированы по домену — клик по строке разворачивает список всех обходов этого сайта с датами, Health Score и числом ошибок. Это удобно, чтобы видеть динамику: стало лучше или хуже после правок.

Расписания (еженедельно / ежемесячно) создаются в поле «Регулярность» при запуске. Scheduler-воркер раз в минуту проверяет, пора ли запустить следующий обход, и использует те же настройки — скорость, глубина, User-Agent, паттерны, — что были у исходного обхода. После каждого завершения вы получите письмо на почту, если включена опция «Уведомить при завершении».
Все результаты можно выгрузить в трёх форматах: CSV (простая таблица всех страниц), XLSX (многолистовой файл с разбивкой проблем по категориям), PDF (готовый отчёт для клиента). Кнопки экспорта — в строке задачи и в правом верхнем углу страницы отчёта. Подробности — в статье CSV, XLSX и PDF.
Сводка по всем сайтам
Если вы работаете с несколькими проектами — на дашборде есть блок «Сводка по всем сайтам», где в одном месте видны общие метрики: сколько URL суммарно проверено, средний Health Score, число критичных ошибок и предупреждений. Удобно для агентств и инхаус-команд, которые ведут десятки сайтов.

Частые вопросы
Как запустить обход сайта в SEO Crawler?
Откройте /dashboard, вставьте URL сайта в поле «URL сайта» в блоке «Новый парсинг», при необходимости задайте «Макс. URL» и нажмите «Запустить». Обход появится в таблице «Задачи» со статусом «В очереди», затем перейдёт в «Выполняется» и «Готово». Результат открывается кликом на строку с доменом.
Сколько страниц обходит SEO Crawler за один раз?
Лимит задаётся в поле «Макс. URL» при создании обхода. Максимум зависит от тарифа: Free — до 50 страниц, Pro и Trial — до 500. Если сайт больше — краулер остановится на лимите и покажет сообщение, что обход завершён по ограничению.
Что делать, если сайт содержит тысячи страниц?
Используйте шаблоны в расширенных настройках — «Парсить только» и «Не парсить» — чтобы ограничить обход конкретными разделами (/blog/*, /products/*). Или установите «Макс. глубина» — например, 2, чтобы обойти только главную и разделы первого уровня. Для полного обхода большого сайта понадобится тариф Pro.
Какая скорость обхода у краулера?
По умолчанию 1,5 запроса в секунду. В расширенных настройках скорость регулируется ползунком от 0,1 до 3 RPS. Низкая скорость подходит для слабых серверов и общего хостинга, высокая — для крупных сайтов на своих серверах. Краулер также уважает директиву Crawl-delay в robots.txt.
Почему некоторые страницы пропущены в отчёте?
Чаще всего причины три: страница закрыта в robots.txt через Disallow, на странице стоит meta robots noindex/nofollow, или до неё просто нет внутренних ссылок (orphan-страница). Orphan-страницы краулер не находит — их нужно либо линковать из меню и подвала, либо добавить в sitemap.xml и запустить обход через него.
Что такое BFS и почему краулер использует именно его?
BFS (breadth-first search, обход в ширину) — это алгоритм, при котором краулер сначала обходит все страницы на первом уровне (ссылки с главной), затем на втором (ссылки с разделов) и так далее. В результате при небольшом лимите вы получаете самые важные и популярные страницы сайта — те, что ближе всего к главной.
Какой User-Agent использует краулер?
По умолчанию — SEOCrawlerBot/1.0. В расширенных настройках можно выбрать Chrome, Googlebot или Bingbot — полезно, если сервер по-разному отвечает разным ботам или если вы хотите увидеть сайт глазами поисковика. Подмена User-Agent на Googlebot не должна использоваться для обхода ограничений — это против правил большинства CDN.
Обходит ли SEO Crawler сайты на React и Vue?
Краулер получает исходный HTML от сервера без выполнения JavaScript. Если сайт работает как SPA и контент рендерится в браузере — title, H1 и текст будут пустыми, а внутренних ссылок не будет. Решение — настроить Server-Side Rendering (SSR), Static Site Generation (SSG) или prerender для ботов. Подробнее — в статье «Сайт не обходится».
Платный ли повторный обход того же сайта?
Повторные обходы учитываются как обычные обходы и списываются из месячной квоты тарифа. Если вы на Free — каждый запуск обхода сайта идёт в общий лимит обходов в месяц. Расписания (еженедельно / ежемесячно) доступны на Pro и Trial — они автоматически запускают обход и сравнивают результаты с предыдущим аудитом.
Как посмотреть результаты предыдущих обходов?
На /dashboard в таблице «Задачи» все обходы сгруппированы по домену. Кликните по строке домена — развернётся история всех обходов этого сайта с датами, количеством страниц и Health Score. Каждый обход открывается в своём отчёте и остаётся доступен, пока вы не удалите его вручную.