Проверка HTTP-статусов в SEO Crawler
Каждая страница сайта — это пара «URL → код ответа». Код говорит поисковому роботу, что делать дальше: 2xx — индексировать, 3xx — идти по редиректу, 4xx — пропустить (или деиндексировать, если был в индексе), 5xx — вернуться позже. SEO Crawler во время обхода сохраняет код ответа для каждой страницы, все переходы в цепочке редиректов и флаг has_redirect_loop. В отчёте статусы агрегируются на вкладке «Обзор» в кольце «Статусы» и детализируются на «Технической» и «Все страницы».
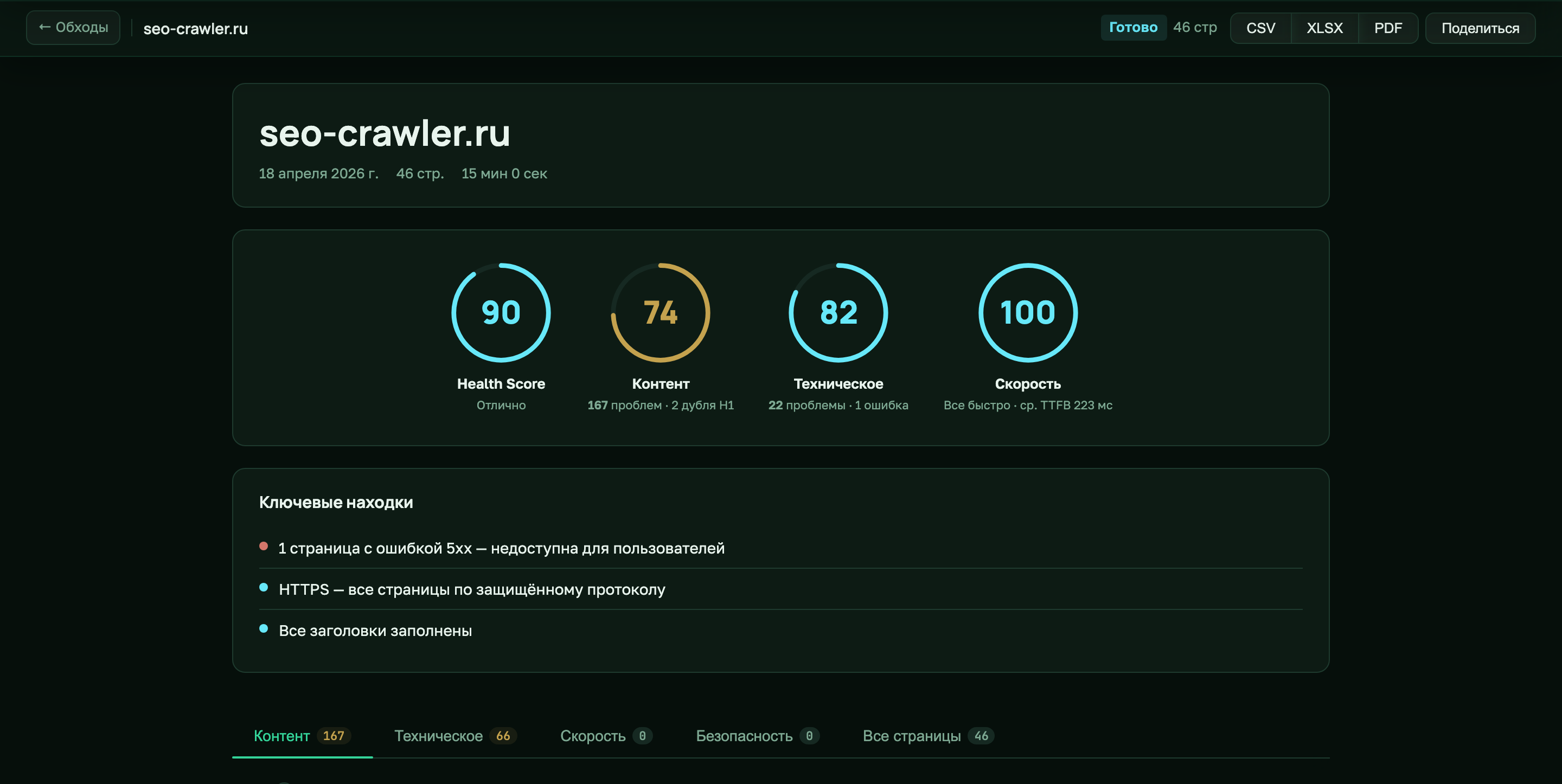
Коды 2xx: страница ответила нормально
Диапазон 200–299 — все варианты успешного ответа. На практике 99% HTML-страниц сайта отдают 200 OK, поисковый робот скачивает их и индексирует. Другие коды 2xx редки в контексте SEO: 201 (Created) — для API-ответов, 204 (No Content) — для AJAX-запросов без тела. В таблице «Все страницы» SEO Crawler показывает 2xx зелёным бейджем OK. Отдельной карточки по 2xx в UI нет — это не проблема, а норма.
Но сам факт 200 не означает, что страница в порядке: страница может быть soft 404 (код 200, но по содержимому «Страница не найдена»), может быть помечена noindex, может иметь пустой контент. Проверки ранжируются именно по содержимому на других вкладках отчёта.
Коды 3xx: редиректы и цепочки
Коды 300–399 — перенаправления. Сервер говорит «эта страница теперь по другому URL». SEO Crawler следует редиректам до 10 прыжков (MAX_REDIRECTS = 10) и сохраняет всю цепочку в поле redirect_chain записи страницы. Самые важные коды:
| Код | Значение | Передаёт ли вес | Когда использовать |
|---|---|---|---|
301 | Moved Permanently | Да, полностью | Переезд страницы навсегда: смена URL, слияние, миграция домена |
302 | Found (temporary) | Нет | Временная заглушка, A/B-тест, сезонный редирект |
303 | See Other | Нет | После POST-запроса — редкий для SEO |
307 | Temporary Redirect | Нет | То же, что 302, но сохраняет метод запроса |
308 | Permanent Redirect | Да | То же, что 301, но сохраняет метод запроса |
Цепочки редиректов
Идеальный редирект — один прыжок: /old → /new. На практике после нескольких миграций часто складываются цепочки: http://www.example.com/old → https://www.example.com/old → https://example.com/old → https://example.com/new → https://example.com/new/. Это четыре прыжка, каждый из которых съедает TTFB, craw-budget и передаёт чуть меньше веса.
Google рекомендует не более 3–5 прыжков в цепочке. Сам Googlebot останавливается после 10. SEO Crawler тоже жёстко ограничивает обход: если цепочка длиннее 10 — используется последний полученный ответ, страница помечается недоступной. В отчёте длинные цепочки видны в таблице «Все страницы» при клике на строку — раскрывается блок redirect-chain со всеми URL и кодами.
Redirect loops (циклические редиректы)
Частный случай ошибки: страница редиректит на саму себя или на URL, который потом редиректит обратно. SEO Crawler детектирует петлю (has_redirect_loop = true), останавливается и ставит в таблице «Все страницы» красный бейдж loop рядом с URL. В таблице при клике на строку виден полный путь, по которому краулер ходил кругами, — обычно это даёт мгновенную подсказку о причине: забытый .htaccess, неправильный trailing slash, конфликт канонического редиректа с www.
Коды 4xx: ошибки клиента
Диапазон 400–499 — сервер получил запрос, но не может или не хочет его обработать. Для SEO интересны четыре кода:
| Код | Значение | Что делает поисковик |
|---|---|---|
403 | Forbidden — доступ запрещён | Не индексирует, может помечать как «заблокировано» |
404 | Not Found — страница не найдена | Не индексирует, деиндексирует после нескольких попыток |
410 | Gone — удалена навсегда | Деиндексирует быстрее, чем 404 |
429 | Too Many Requests — слишком много запросов | Замедляется, не считает за ошибку при редких случаях |
Как SEO Crawler обрабатывает 4xx
Каждая страница с кодом 4xx попадает в таблицу «Все страницы» с красным бейджем статуса. Если на эту страницу ведут внутренние ссылки — они автоматически засчитываются как битые ссылки в карточке «Битые ссылки» раздела «Ссылки» вкладки «Техническое». Клик по карточке раскрывает таблицу: source URL (откуда ссылка), destination URL (куда), код ответа (404/403/410), якорный текст, атрибут rel.
Для тестового обхода SEO Crawler'а по собственному сайту 4xx обычно не найдётся — страницы справки и лендинга все отдают 200. Если вы тестируете на реальном клиентском сайте, в карточке «Битые ссылки» появятся цифры.

Коды 5xx: ошибки сервера
Диапазон 500–599 — сервер признаёт, что не справился с запросом. Это сигнал о проблеме в вашей инфраструктуре, а не в URL.
| Код | Значение | Типичная причина |
|---|---|---|
500 | Internal Server Error | Необработанное исключение в backend, синтаксическая ошибка в шаблоне |
502 | Bad Gateway | Nginx не может достучаться до backend (FastAPI/Node/PHP-FPM упал) |
503 | Service Unavailable | Сервер перегружен, плановое обслуживание, rate limit |
504 | Gateway Timeout | Backend не ответил за лимит времени (долгий SQL-запрос, висящий worker) |
Почему 5xx критичны для SEO
Единичная 5xx ошибка не страшна — Googlebot попробует вернуться через некоторое время. Но если поисковик регулярно видит 5xx при обходе, он сначала замедляется, потом начинает помечать страницу как недоступную, а в итоге может убрать её из индекса. При массовых 5xx страдает ранжирование сайта целиком.
SEO Crawler показывает страницы с 5xx в таблице «Все страницы» с красным бейджем и агрегирует в карточке «Битые ссылки» вместе с 4xx (обе группы — источник потери веса). В XLSX страницы с 5xx попадают на лист Broken links с указанием конкретного кода.
«Страницы с ошибками»: где смотреть в UI
Основное место для поиска проблемных URL — таблица «Все страницы». В ней каждая строка — это URL, и первая колонка после адреса — Код с цветным бейджем: зелёный для 2xx, синий для 3xx, жёлтый для 4xx, красный для 5xx. Рядом с URL при цикле редиректов появляется красный бейдж loop.
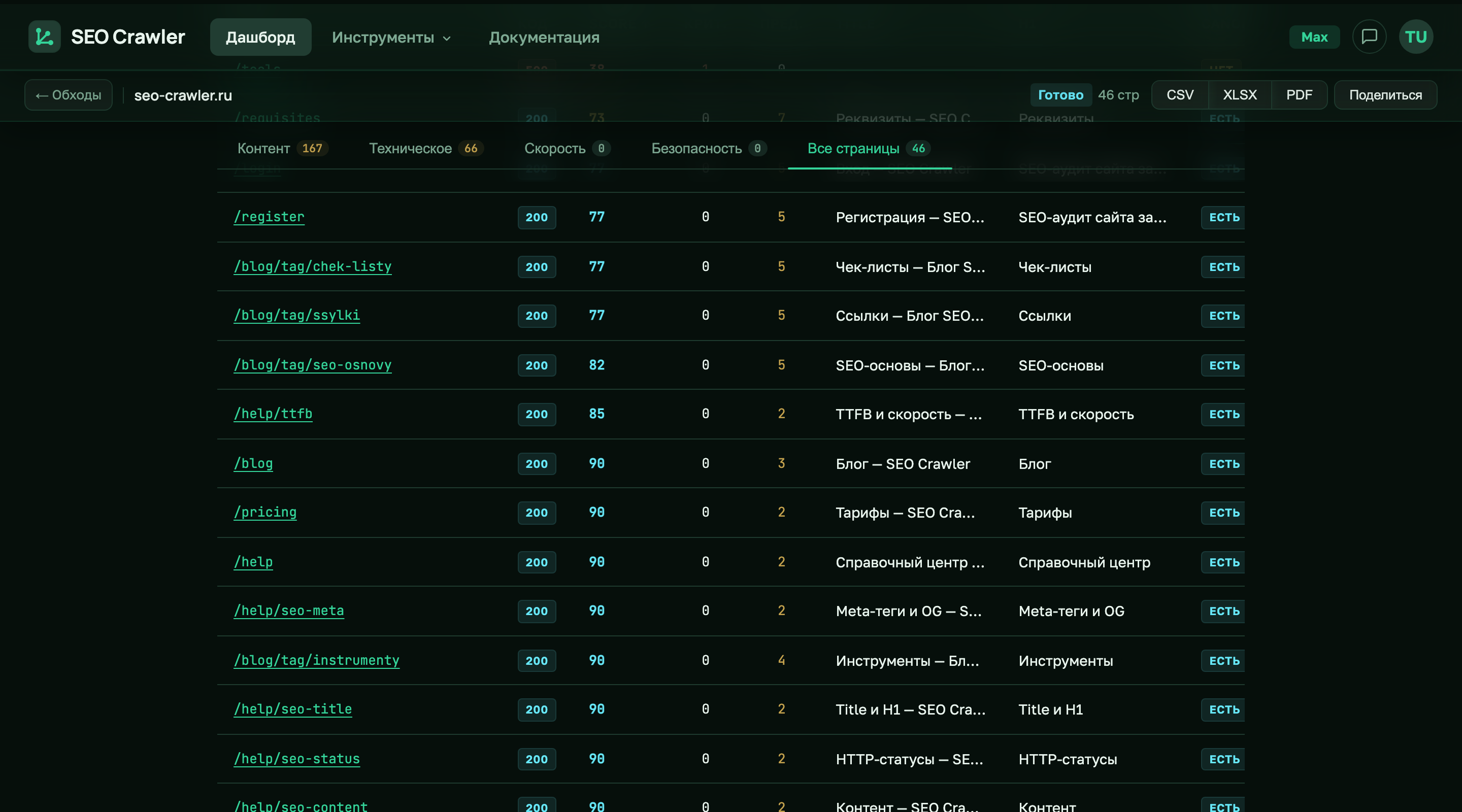
Для фильтрации по кодам используйте сортировку колонки Код — проблемные страницы соберутся в начале или в конце списка. Над таблицей есть поиск по URL — если нужно быстро найти одну конкретную страницу и увидеть её статус.
Экспорт проблемных URL в XLSX
Кнопка XLSX в шапке отчёта собирает все проблемные URL в Excel-файл. Листы, относящиеся к HTTP-статусам:
| Лист в XLSX | Что внутри |
|---|---|
Broken links | Внутренние ссылки на 4xx/5xx: from, to, status, text, rel. По этому листу работаете с разработчиком |
Redirect links | Внутренние ссылки на 3xx: from, to, финальный URL, длина цепочки |
Redirect loops | Страницы с циклическими редиректами, полная цепочка URL |
All pages | Полный дамп: URL, status_code, response_time_ms, redirect_count, has_redirect_loop, redirect_chain |
Для массовых правок чаще всего достаточно листа Broken links: сортируете по status, группируете по source URL, передаёте разработчику. Подробнее обо всех листах — в разделе Экспорт CSV / XLSX / PDF.
Недоступные страницы
Отдельный класс проблем — страницы, с которых SEO Crawler вообще не получил HTTP-ответа. Причины:
- Таймаут — сервер не ответил за отведённое время.
- DNS-ошибка — домен не резолвится.
- Сброс соединения — WAF, файрвол или Cloudflare отбили запрос на уровне TCP.
- SSL-ошибка — сертификат истёк, самоподписанный или не совпадает с доменом.
Такие URL в таблице «Все страницы» показываются со статусом «—» или с серым бейджем «Недоступно». Если проблема массовая и отдельные группы URL недоступны у SEO Crawler, но доступны у пользователей — читайте Help → Сайт не обходится: там разобраны типичные причины и их диагностика.
Что делать после правок
После того как вы настроили 301-редиректы на удалённые страницы, починили 404, решили проблемы с 5xx или убрали redirect loops — запустите повторный обход в SEO Crawler и сравните счётчики с предыдущим отчётом. Обычно правки HTTP-статусов — самые «отзывчивые»: вы сразу видите, как «Битые ссылки: 47 → 0» или «Redirect loops: 3 → 0». Эти цифры удобно приложить к отчёту клиенту: сайт «стал чище» буквально за один деплой.
Частые вопросы
Чем 301-редирект отличается от 302?
301 (Moved Permanently) — страница переехала навсегда, поисковик передаёт вес на новый URL и обновляет индекс. 302 (Found) — временный редирект, вес не передаётся, в индексе остаётся старый URL. При миграции сайта, смене структуры URL или слиянии страниц используйте 301. 302 оправдан только для временных ситуаций: A/B-тест, временная заглушка, региональный редирект по гео. SEO Crawler собирает оба типа в колонке redirect_chain и показывает финальный URL.
Когда 404 — это норма, а когда проблема?
Норма: запрос несуществующего URL напрямую (пользователь ошибся в адресе, скраперы ищут /wp-admin). Google Search Console сам пишет, что такие 404 можно игнорировать. Проблема: на 404 ведут внутренние ссылки с других страниц сайта, на 404 ведут внешние ссылки (теряется ссылочный вес), страница была в индексе и вдруг стала 404 (типично после миграции). SEO Crawler показывает 404 на вкладке «Техническое» → раздел «Ссылки» → карточка «Битые ссылки» и выгружает в XLSX с указанием source URL.
Почему страница даёт 200 в браузере, но 403 SEO Crawler'у?
Скорее всего сервер фильтрует по User-Agent, IP или Referrer. SEO Crawler по умолчанию представляется как собственный UA и идёт с одного IP. Cloudflare, Imunify360, WAF-правила часто блокируют «подозрительных ботов» — браузер человека пропускают, а краулер получает 403. Решения: добавьте IP SEO Crawler в белый список или разрешите UA SEO-Crawler в правилах WAF. Такая же проблема возникает у Googlebot — стоит разблокировать сразу всех.
Сколько редиректов в цепочке считается критичным?
Больше трёх — уже проблема. Google в документации рекомендует максимум 3–5 прыжков, после 10 Googlebot останавливается. SEO Crawler жёстко ограничивает обход десятью редиректами (MAX_REDIRECTS = 10): если цепочка длиннее, берётся последний полученный ответ, и страница помечается как недоступная. Оптимально — 1 прыжок (старый URL → новый URL). Длинные цепочки обычно возникают при накоплении ошибок миграций: https://www → https → /new-path → с trailing-slash.
Как решить ошибку 429 Too Many Requests?
429 — сервер ограничил частоту запросов с вашего IP. Для SEO Crawler уменьшите скорость обхода в настройках задачи: например, 1 запрос в секунду вместо 5. Если ошибка приходит от реальных пользователей — проверьте rate-limit правила на сервере или WAF: возможно, вы случайно заблокировали подсети мобильных операторов или корпоративных NAT. 429 от поисковиков — редкость, но если случается, Googlebot воспринимает это как сигнал «снизь частоту» и временно замедляется.
Как решить массовые 503 Service Unavailable?
503 значит «сервер перегружен» или «на обслуживании». Если в отчёте много 503 — проверьте нагрузку (CPU, память), логи backend'а, не умирает ли процесс от OOM. Если 503 только на определённых страницах (корзина, админка) — возможно, таймаут базы данных или долгий SQL-запрос. Для временных работ на сервере корректно отдавать 503 с заголовком Retry-After — поисковик увидит, что это временно, и не удалит страницу из индекса. 503 без Retry-After на несколько часов уже приводит к выпадению из индекса.
SEO Crawler игнорирует noindex при коде 200?
Нет, но работает с этим хитро: страница с noindex обходится, HTML парсится, данные собираются — и в отчёте она помечается в карточке «Noindex» на вкладке «Техническое» → раздел «Индексация». Это сделано специально: в реальности Googlebot тоже скачивает noindex-страницы, просто не индексирует их. Вам важно видеть noindex-страницы в отчёте — хотя бы потому, что на них часто по ошибке попадают контентные страницы (не забыли ли убрать noindex со staging-версии после релиза на прод).
Почему страница есть в sitemap, но 404 при обходе?
Классический симптом устаревшего sitemap.xml. Скорее всего страница была удалена или переименована, а sitemap продолжает её отдавать — так бывает при статической генерации sitemap без синхронизации с БД. Для SEO это двойная проблема: поисковик получает сигнал «у меня есть эта страница», идёт на неё и видит 404. Решение — пересобрать sitemap или выгружать его динамически из актуального списка URL. SEO Crawler не сверяет sitemap с индексом автоматически, но список URL в отчёте можно сопоставить с sitemap вручную.
Как найти все битые ссылки на сайте оптом?
Запустите полный обход в SEO Crawler — краулер пройдёт по всем внутренним ссылкам, проверит коды ответов и соберёт битые в карточку «Битые ссылки» на вкладке «Техническое». Выгрузка — в XLSX на листе Broken links с колонками from / to / status / text / rel. Для проверки одной конкретной страницы (без полного обхода) есть инструмент «Битые ссылки» — вставляете URL и получаете список до 100 ссылок с этой страницы и их кодов.
Откуда SEO Crawler берёт URL для обхода, если не из sitemap?
SEO Crawler работает в BFS-режиме: начинает с начального URL (обычно главной), парсит её HTML, вытаскивает все <a href> на тот же домен и добавляет их в очередь. Дальше аналогично с каждой новой страницей — до достижения лимита глубины или количества URL. Sitemap.xml краулер использует как дополнительный источник, если он доступен, но основа — живой обход по ссылкам. Это значит, что orphan-страницы (на которые нет внутренних ссылок) в отчёт не попадут, даже если они есть в sitemap.