Проверка ссылок, canonical и alt в SEO Crawler
Ссылочная структура — это «скелет» сайта для поисковика. По внутренним ссылкам краулеры находят новые страницы, распределяют вес между ними и понимают иерархию разделов. Canonical подсказывает, какой из нескольких URL считать основным. Alt у изображений отвечает одновременно и за доступность, и за попадание картинок в поиск. SEO Crawler собирает эти проверки во время обхода сайта и показывает результаты на вкладках «Техническое» (canonical, ссылки, redirect loops) и «Контент» (alt-атрибуты).
Canonical URL: шесть проверок
Тег <link rel="canonical"> сообщает поисковику, какой URL считать основным для страницы. Без canonical один и тот же контент, доступный по нескольким адресам (с UTM-метками, с параметрами фильтров, с www и без), воспринимается как несколько разных страниц — и вес распределяется между ними. SEO Crawler проверяет не только «есть ли canonical», но и консистентность сигналов.

Без canonical
Тег <link rel="canonical"> в <head> не найден или пустой. Это не критическая ошибка — поисковик всё равно проиндексирует страницу, — но и не лучшая практика: на любом крупном сайте рано или поздно появляется второй URL с тем же контентом (параметр сортировки, версия для печати, UTM-метка), и без self-canonical вы будете разбираться, почему в индексе два варианта.
Canonical указывает на другой URL
SEO Crawler подсвечивает страницу, если canonical указывает не на неё саму, а на другой URL. Это допустимо для технических страниц (версия для печати, AMP-версия, страница с параметрами сортировки), но опасно для контентных: указанный в canonical URL «забирает» себе весь вес и видимость, а текущая страница выпадает из индекса. Проверьте, что canonical на контентной странице указывает на неё саму.
Canonical на чужой домен
Самый опасный случай: canonical ведёт на URL, хост которого не совпадает с доменом обхода. Чаще всего это бывает при миграции с одного домена на другой, когда забыли обновить canonical в шаблоне. Поисковик в этой ситуации исключит страницу из индекса и будет считать оригиналом указанный внешний URL.
Canonical на зеркало (http / https / www)
Страница отдаётся по https://example.com/page, а canonical указывает на http://example.com/page или на https://www.example.com/page. Это конфликт сигналов между основной версией и canonical. Решение — склейка зеркал через 301-редирект и единый формат canonical по всему сайту.
Относительный canonical
Canonical записан как /page без протокола и домена. Формально это работает, но на практике разные поисковики и краулеры интерпретируют относительные URL по-разному. SEO Crawler рекомендует всегда использовать абсолютные URL с https://.
Canonical + noindex
Страница содержит одновременно <meta name="robots" content="noindex"> и self-canonical. Это противоречивые сигналы: noindex говорит «не индексируй эту страницу», а canonical говорит «эта страница — оригинал, индексируй её». Нужно убрать один из двух: если страница служебная — оставить noindex и убрать canonical; если контентная — убрать noindex.
href в canonical тоже считается отсутствием. Перед массовой правкой canonical на продакшене всегда прогоняйте обход на staging и проверяйте, что ни одна карточка не подсветилась красным.Битые внутренние ссылки
Ссылки внутри сайта, ведущие на страницы с кодом 4xx или 5xx. Для SEO опасны тройным образом: передают меньше веса (404 не принимает PageRank), тратят краулинговый бюджет и портят поведенческие факторы — пользователь, попавший на 404, уходит сразу.
SEO Crawler собирает все внутренние ссылки во время обхода и сверяет статус назначения с фактическим кодом, который вернул сервер. Результат — в карточке «Битые ссылки» раздела «Ссылки» на вкладке «Техническое». Клик по карточке раскрывает таблицу: откуда ссылка (source URL), куда ведёт (destination URL), код ответа, якорный текст и атрибут rel.

Что ещё проверяется в разделе «Ссылки»
- Ссылки на редиректы — внутренние ссылки, ведущие на URL с кодом 3xx. Формально не битые, но лишний прыжок съедает crawl budget и замедляет рендер. Проще заменить ссылку на финальный URL.
- Nofollow внутренние ссылки — ссылки с
rel="nofollow"на свой же домен. Внутри сайта nofollow нужен редко; обычно это остатки от старых правил или плагинов. - Проблемы якорного текста — пустой анкор, анкор «тут», «читать далее», дубли анкоров по разным URL. Качественный анкор помогает поисковику понять контекст ссылки.
- Сироты (0 внутр.) — страницы, на которые не ведёт ни одна внутренняя ссылка с других обойдённых страниц. Краулер нашёл их через sitemap или начальный URL, но перелинковки нет.
- Мало входящих ссылок — страницы с одной-двумя входящими внутренними ссылками: не orphan, но почти. На такие URL поисковик редко заходит и плохо ранжирует.
- Много внешних (>50) — страницы с большим числом исходящих ссылок на другие домены. Часто признак спам-футера или автоматически сгенерированного блога.
Для отдельной проверки конкретной страницы (без полного обхода) есть инструмент «Битые ссылки» — вставляете один URL и получаете список всех ссылок с этой страницы и их статусов, до 100 штук.
Изображения без alt
Атрибут alt у тега <img> — альтернативный текст. Он нужен для трёх вещей одновременно: поисковые роботы Google Images и Яндекс Картинок используют alt для ранжирования изображений, скринридеры читают его вслух незрячим пользователям, а браузер показывает alt, если картинка не загрузилась.
SEO Crawler считает изображения без alt или с пустым alt на каждой странице во время обхода и агрегирует результат в карточке «Без alt (все)» раздела «Структура и контент» на вкладке «Контент».

Клик по карточке раскрывает таблицу с URL страниц и количеством проблемных картинок на каждой. Для агентства удобнее выгрузить данные в XLSX: лист Imgs without alt содержит URL, количество <img> без alt и общее количество картинок на странице — можно сразу оценить масштаб.
alt="": скринридер пропустит такое изображение и не будет читать лишнее. SEO Crawler пустой alt засчитывает как «без alt» — это не идеально, но безопаснее: большинство декоративных картинок сегодня лучше выводить как CSS background, а не как <img>.Внутренняя перелинковка
В таблице «Все страницы» для каждого URL видно количество внутренних и внешних ссылок, исходящих со страницы, и количество входящих внутренних ссылок (колонка Ссылки на страницу). Это быстрый способ найти перекосы: страницы с 0–1 входящими ссылками не получат веса от остального сайта, а страницы с сотнями исходящих ссылок размывают свой PageRank.
Что считается внутренней ссылкой
SEO Crawler нормализует хост при сравнении: ссылки /page, https://example.com/page, https://www.example.com/page с обхода example.com — все считаются внутренними. Ссылки с протоколом mailto:, tel:, javascript: и якорные (#section) в подсчёт не попадают. Поддомены blog.example.com при обходе основного домена считаются внешними.
Orphan pages: как их находит SEO Crawler
Для краулера orphan — страница, которую он получил из sitemap.xml или начального URL, но на которую не нашёл ни одной внутренней ссылки в процессе обхода. Карточка «Сироты (0 внутр.)» в разделе «Ссылки» показывает число таких страниц; клик раскрывает список URL. Это частая ситуация для блоговых архивов (страницы тегов) или технических страниц, на которые нет ссылки из меню и которые забыли добавить в перелинковку. Чуть «мягче» карточка «Мало входящих» — одна-две входящие ссылки: до этих страниц краулер доходит, но они всё равно слабо связаны с остальным сайтом.
Полноценный 100% поиск orphan через один инструмент невозможен: страницы, которых нет ни в sitemap, ни в ссылках с других страниц, ни в логах — существуют только в файловой системе/БД CMS и не видны никаким внешним инструментом. Для максимально полного списка сверяйте URL из отчёта SEO Crawler с выгрузкой из CMS или с логами веб-сервера.
Внешние ссылки и nofollow
Ссылки на другие домены учитываются отдельным счётчиком в таблице «Все страницы». Много внешних ссылок со страницы — не проблема сама по себе (это нормально для обзорных статей), но важно, чтобы каждая ссылка вела на релевантный авторитетный источник. Ссылки на рекламные площадки, партнёрские программы и UGC-комментарии обычно закрывают атрибутом rel="nofollow" или rel="ugc", чтобы не передавать им вес.
SEO Crawler собирает суммарное количество внешних ссылок по всему сайту и отдельно — количество nofollow-ссылок. В XLSX на листе All pages каждой странице соответствуют колонки internal_links, external_links, nofollow_external. Если число внешних ссылок резко выросло между двумя обходами — возможно, сайт взломали и добавили спам-ссылки.
Экспорт в XLSX
Кнопка XLSX в шапке отчёта собирает все ссылочные проверки в один Excel-файл. Листы, относящиеся к теме этой статьи:
| Лист в XLSX | Что внутри |
|---|---|
Broken links | Колонки: from (откуда), to (куда), status (код ответа), text (якорь), rel. Только внутренние ссылки на 4xx/5xx |
Redirect links | Внутренние ссылки, ведущие на 3xx-редиректы, с финальным URL и длиной цепочки |
Missing canonical | Страницы без тега canonical или с пустым href |
Canonical issues | Conflict-группа: canonical на другой URL, на чужой домен, на зеркало, относительный, canonical+noindex |
Imgs without alt | URL страницы, количество <img> без alt и общее число изображений на странице |
All pages | Полный дамп: URL, status, canonical, internal_links, external_links, nofollow_external, images_total, images_without_alt |
Подробнее обо всех листах и форматах — в разделе Экспорт CSV / XLSX / PDF.
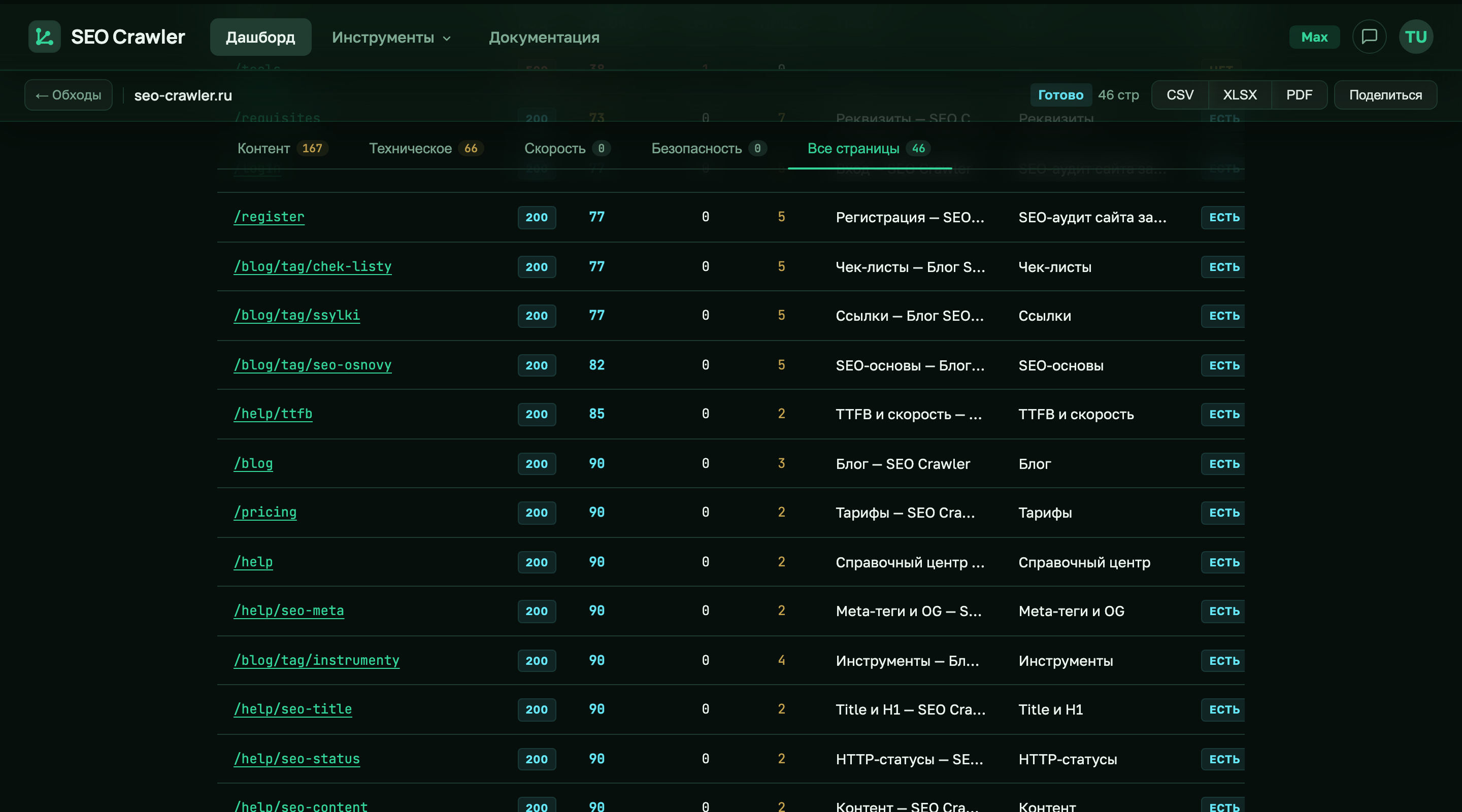
Таблица «Все страницы»: canonical и ссылки в одной строке
На вкладке «Все страницы» каждая строка — это URL со всеми агрегированными метриками: статус, Health Score, количество критических и предупреждений, canonical (есть / нет / отличается от URL), число входящих и исходящих внутренних ссылок, число изображений без alt. Это удобный способ глазами пробежать сайт и заметить, например, что все карточки товаров имеют canonical на главную — такие массовые аномалии видны сразу.
Что делать после правок
Когда вы поправили canonical в шаблоне CMS, заменили битые ссылки или добавили alt к картинкам — запустите повторный обход в SEO Crawler и сравните счётчики с предыдущим отчётом. Динамика «было 47 битых — стало 2» наглядно показывает прогресс, и этот отчёт удобно прикрепить к задаче клиенту или руководителю. Если правите частями — сначала canonical, потом битые ссылки, потом alt — запускайте обход после каждого этапа, чтобы видеть эффект изолированно и не путать причину с результатом.
Частые вопросы
Canonical должен вести на HTTPS или HTTP?
На HTTPS, если сайт работает по HTTPS. Canonical на HTTP-версию при фактическом HTTPS — типичная ошибка зеркала: поисковик получает противоречивый сигнал, потому что запрашивает страницу по https://, а canonical указывает на http://. SEO Crawler подсвечивает такие случаи в карточке «Canonical на зеркало» на вкладке «Техническое» — сюда же попадают конфликты www / без www.
Почему SEO Crawler говорит «canonical-конфликт», если тег стоит?
Конфликт — это не «нет canonical», а «canonical противоречит остальным сигналам». Типичные случаи: canonical указывает на другой URL, canonical на чужой домен, canonical на зеркало (http/https или www), canonical относительный (без https://), canonical + noindex одновременно. Все шесть проверок лежат в разделе «Canonical» на вкладке «Техническое»; каждая имеет свою карточку со счётчиком.
Считается ли nofollow-ссылка битой?
Нет. Nofollow — это только инструкция для поисковика не передавать вес по этой ссылке; сама ссылка рабочая и отдаёт 200. SEO Crawler считает битыми только ссылки, ведущие на 4xx/5xx внутренние URL. Nofollow-внутренние ссылки идут отдельным счётчиком «Nofollow внутренние ссылки» в разделе «Ссылки» вкладки «Техническое» — обычно это подозрительно: внутри сайта nofollow нужен редко.
SEO Crawler проверяет orphan pages?
Да. В разделе «Ссылки» вкладки «Техническое» есть отдельная карточка «Сироты (0 внутр.)» — страницы, которые краулер нашёл (через sitemap или начальный URL), но на которые не ведёт ни одна внутренняя ссылка с других обойдённых страниц. На тестовом обходе seo-crawler.ru таких страниц 21 — в основном технические и блоговые архивы. Рядом — карточка «Мало входящих» (одна-две ссылки), приближённый аналог.
Как найти все изображения без alt оптом?
Откройте отчёт → вкладка «Контент» → раздел «Структура и контент» → карточка «Без alt (все)». Цифра показывает, на скольких страницах есть хотя бы одно изображение без alt. Под ней — раскрытый блок «Без alt-атрибута» с таблицей: URL страницы и сколько на ней картинок без alt. Массовая выгрузка — в XLSX на листе Imgs without alt. Для контент-менеджера удобнее всего отсортировать лист по числу проблемных картинок и начать с худших страниц.
Влияет ли alt на SEO или это только про доступность?
Влияет. Alt используют Google Images и Яндекс Картинки для ранжирования изображений — без alt картинка не попадёт в поиск по изображениям. Alt также подставляется в анкор ссылки, если изображение обёрнуто в <a>: без него поисковик не понимает, куда ведёт ссылка. Плюс доступность для скринридеров и фолбэк при ошибке загрузки. Пустой alt="" разрешён для чисто декоративных картинок (разделителей, паттернов фона).
Что считается внутренней ссылкой?
Любой <a href>, у которого хост совпадает с хостом обхода — с учётом www и без. SEO Crawler нормализует хост (обрезает www, приводит к нижнему регистру), поэтому ссылки вида //example.com/foo, /foo, https://www.example.com/foo с обхода example.com все считаются внутренними. Ссылки с протоколом mailto:, tel:, javascript: и якорные (#anchor) в счётчик не попадают.
SEO Crawler проверяет hreflang?
На уровне аудита — ограниченно: теги <link rel="alternate" hreflang> собираются на каждой странице, но отдельной карточки в UI по ошибкам hreflang сейчас нет. Для детальной проверки одного URL быстрее использовать инструмент валидатор hreflang: он валидирует коды языков и регионов по ISO, проверяет наличие x-default, обратные ссылки между версиями и несовпадение URL. Этот инструмент доступен без обхода сайта.
Ссылки внутри JS-скриптов учитываются?
Нет. SEO Crawler читает только HTML, отданный сервером, и парсит <a href> в нём. JavaScript не исполняется — если ссылка появляется на странице после гидрации фреймворка (React, Vue, Next.js без SSR), краулер её не увидит. Это же ограничение у Googlebot до фазы второго рендера, поэтому для SEO важно, чтобы ключевые ссылки отдавались в статическом HTML. Если сайт SPA — включите SSR или prerender.
Какую глубину обхода ставить для большого сайта?
Зависит от структуры. Для интернет-магазина с плоской архитектурой (категория → товар) хватает глубины 3–4. Для блога с пагинацией, тегами и архивами — 5–6. Больше 8 почти никогда не нужно: если до страницы нужно больше 8 кликов с главной, она уже плохо индексируется. В настройках обхода вы также ограничиваете количество URL — ставьте лимит с запасом 20% к sitemap.xml, чтобы покрыть и страницы без ссылок в нём.