Проверка meta-тегов в SEO Crawler
Во время обхода сайта SEO Crawler читает <head> каждой страницы и собирает meta-теги, которые влияют на то, как сайт выглядит в поисковой выдаче, в соцсетях и как его обрабатывают краулеры. В отчёте об аудите вы увидите, на каких URL отсутствует description, слишком короткий или длинный, где не заполнены Open Graph-теги, где стоит noindex, не задан атрибут lang или viewport. Проверки разнесены между вкладками «Контент» (description, OG) и «Техническое» (индексация, canonical, viewport, lang).
lang, viewport). Карточки с ненулевыми счётчиками подсвечиваются жёлтым (предупреждение) или красным (ошибка).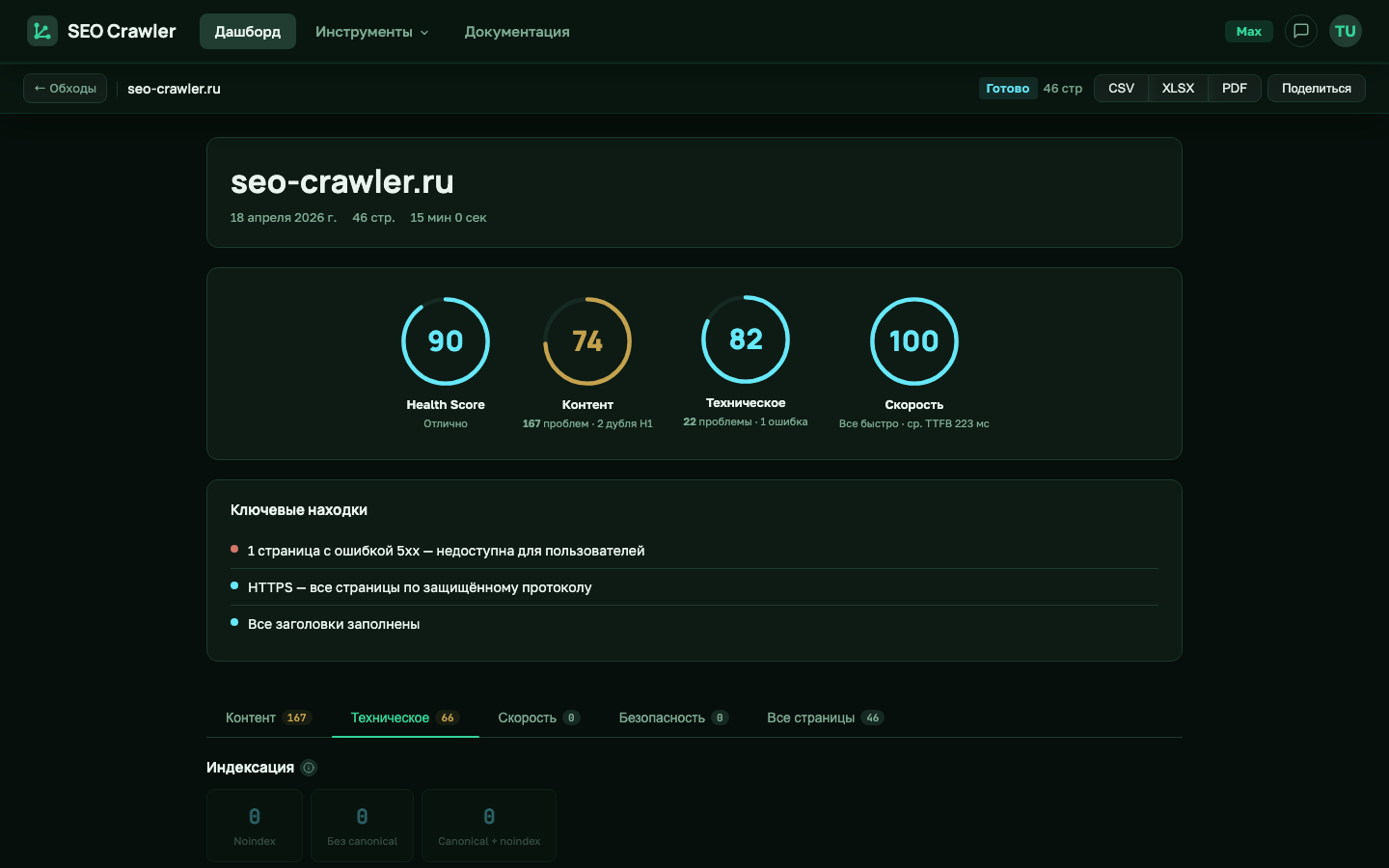
Meta Description
Тег <meta name="description"> — короткое описание страницы, которое поисковик использует для формирования сниппета в выдаче. Напрямую на ранжирование он не влияет, но определяет CTR: привлекательный сниппет получает больше кликов, а поведенческие факторы учитываются при ранжировании.
SEO Crawler собирает description со всех страниц сайта и группирует их в раздел «Описания» на вкладке «Контент». Пять карточек показывают, сколько страниц попали в каждую проблему.
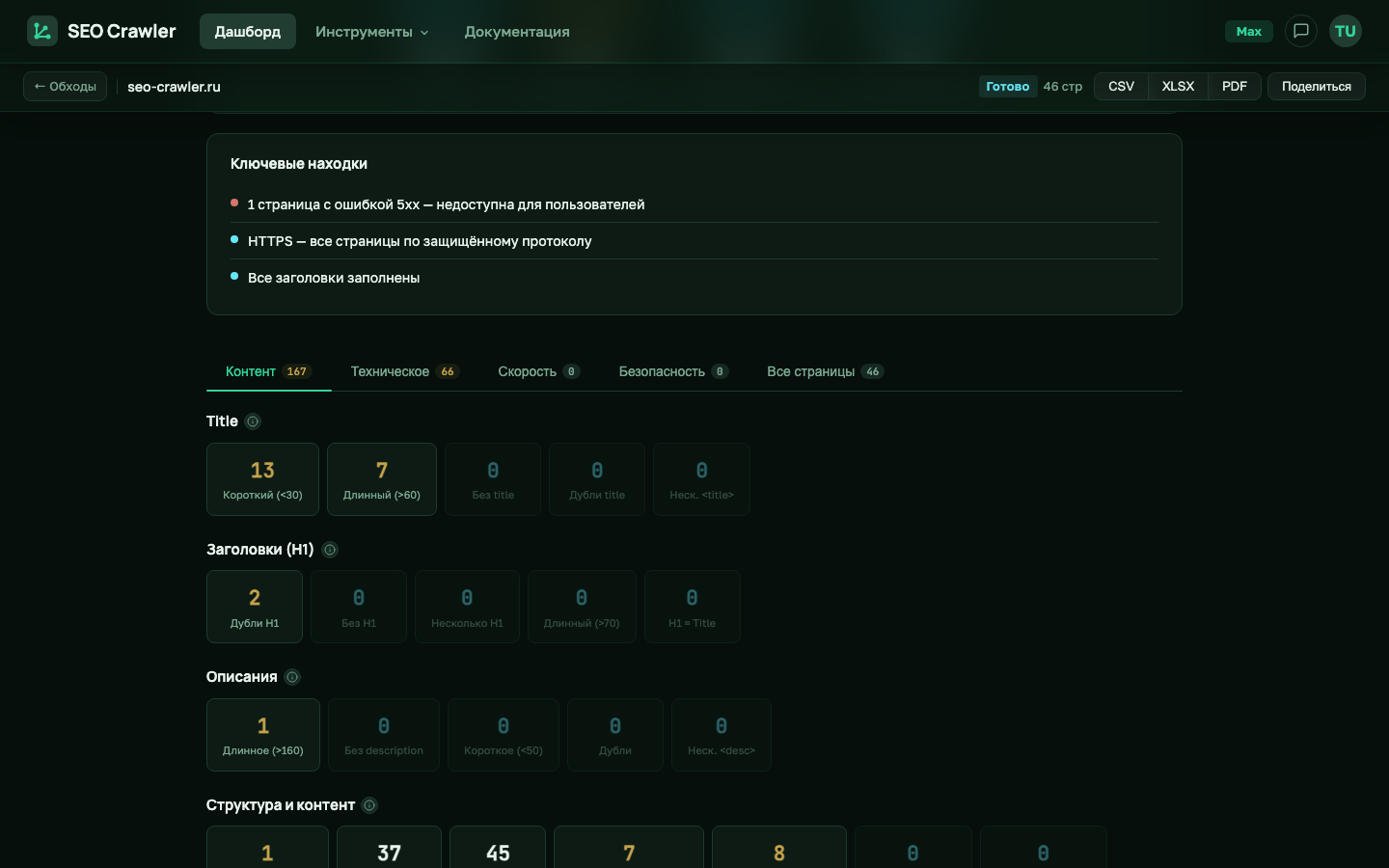
Что считаем проблемой
| Карточка | Критерий | Лист в XLSX |
|---|---|---|
| Без description | Тег <meta name="description"> не найден или пустой |
Missing description |
| Короткое (<50 символов) | Недостаточно информации для формирования полезного сниппета | Desc length issues |
| Длинное (>160 символов) | Хвост обрежется в выдаче Google, важная информация будет потеряна | Desc length issues |
| Дубли | Одинаковый description на нескольких URL | Duplicate descriptions |
| Несколько <description> | На странице найдено более одного meta-тега description — поисковик сам выберет | Missing description |
Кликните по карточке — откроется таблица с URL всех затронутых страниц и текущим значением description. Это же попадает в XLSX-отчёт на соответствующий лист.
Open Graph: og:title, og:description, og:image, og:url
Open Graph — протокол Facebook, который стал стандартом для превью ссылок во всех крупных соцсетях и мессенджерах: Telegram, VK, X/Twitter, LinkedIn, WhatsApp, Facebook, Slack, Discord. Без OG-тегов платформа сама выбирает, какую картинку и заголовок подставить в карточку — результат обычно непривлекательный: случайная иконка с сайта, title из вкладки браузера.
SEO Crawler проверяет пять ключевых OG-тегов в разделе «Open Graph» на вкладке «Контент».
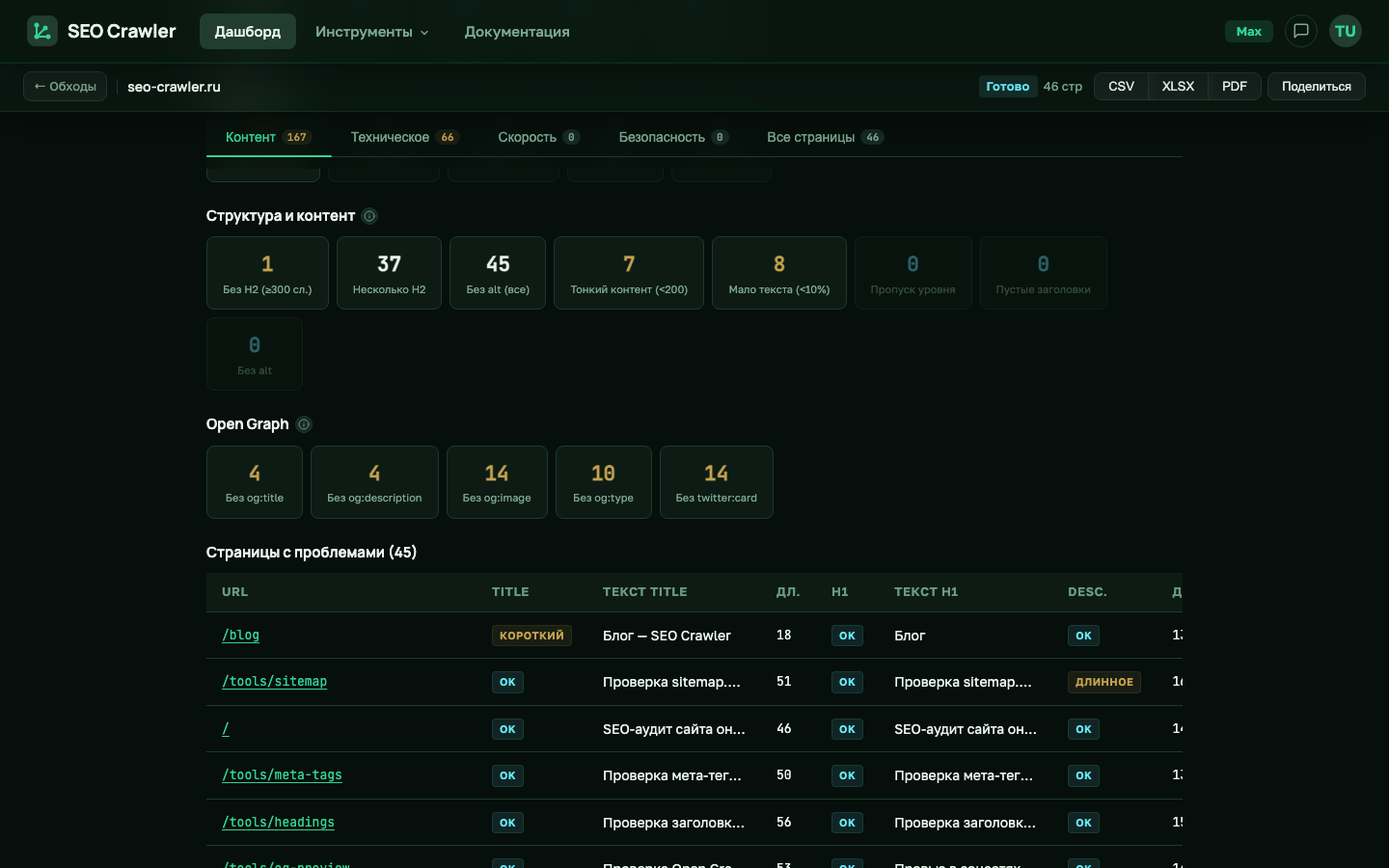
Что проверяем
- og:title — заголовок превью. Часто его делают таким же, как
<title>, но иногда пишут отдельно — более «продающим», потому что у соцсетей другой контекст, чем у SERP. - og:description — описание превью. Без него платформы берут meta description или первый абзац текста.
- og:image — главный элемент превью. Именно картинка определяет, остановится ли пользователь на вашей ссылке в ленте.
- og:type — тип контента:
website,article,product. Влияет на то, как Facebook классифицирует страницу. - twitter:card — формат превью в X/Twitter. Обычно
summary_large_image.
Требования к og:image
Размер: 1200×630 пикселей — оптимум для всех платформ. Минимум — 600×315. Меньшие изображения Facebook не покажет крупным превью, а обрежет в квадрат. Формат: JPG или PNG. SVG не подходит — большинство мессенджеров его не рендерят в превью.
Если og:image отсутствует, SEO Crawler покажет число таких страниц в карточке «Без og:image». Перед массовыми правками полезно посмотреть, как превью реально выглядит — для этого в проекте есть отдельный инструмент превью Open Graph: вставляете URL и видите карточку так, как её увидит Telegram, VK и Facebook.
?v=2 к URL и заново пошерить.Meta Robots: noindex, nofollow
Тег <meta name="robots"> управляет поведением поисковых роботов: разрешена ли индексация страницы и переход по её ссылкам. Самые важные директивы:
- noindex — страница не попадает в выдачу.
- nofollow — ссылки со страницы не передают вес (применимость ограничена — Google давно относится к nofollow как к «подсказке»).
- none — эквивалент
noindex, nofollow.
SEO Crawler следует этим директивам при сканировании (страница сканируется, но помечается), а в отчёте показывает их в разделе «Индексация» на вкладке «Техническое».
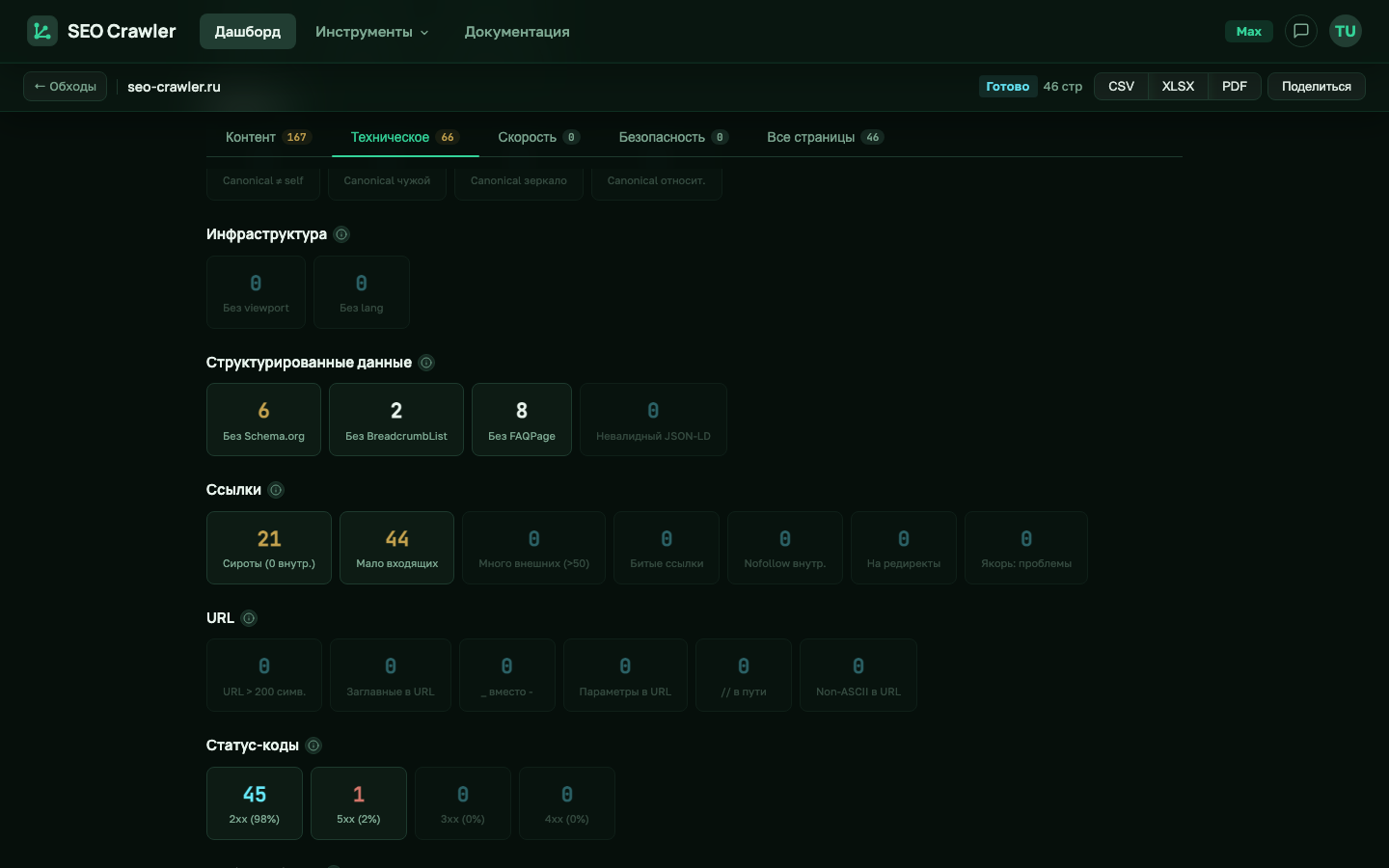
viewport и lang.| Карточка | Критерий | Лист в XLSX |
|---|---|---|
| Noindex | В meta robots найдена директива noindex или none |
Noindex |
| Canonical + noindex | Страница с noindex ссылается сама на себя как canonical — противоречивые сигналы | Canonical issues |
Атрибут lang
Атрибут lang на теге <html> сообщает браузеру и поисковику язык контента. Формально он не обязателен, но в 2026 году его отсутствие стоит рассматривать как ошибку: без lang скринридеры не смогут правильно произнести текст, браузер не предложит автоперевод, а Google может хуже определить регион страницы.
SEO Crawler проверяет наличие атрибута lang в карточке «Без lang» на вкладке «Техническое» → раздел «Инфраструктура».
| Карточка | Критерий | Лист в XLSX |
|---|---|---|
| Без lang | Атрибут lang не задан на теге <html> или пустой |
Missing lang |
Для русскоязычных сайтов используйте <html lang="ru">. Для мультиязычных — язык каждой версии плюс hreflang-теги, о которых подробно в разделе Ссылки и canonical.
Viewport и charset
Два тега базовой валидности HTML-head:
- viewport —
<meta name="viewport" content="width=device-width, initial-scale=1">. Без него сайт на мобильном открывается в «десктопной» ширине и не масштабируется — Google в Mobile-Friendly Test ругается и понижает в мобильной выдаче. - charset —
<meta charset="utf-8">. Без корректной кодировки кириллица и смайлы могут отображаться каккркозябшики. Все современные CMS ставят charset по умолчанию, но на самописных сборках это иногда забывают.
SEO Crawler отдельно проверяет только viewport в карточке «Без viewport» раздела «Инфраструктура» на вкладке «Техническое». Проблемы с charset обычно проявляются иначе — битые символы в title или H1, которые вы заметите визуально в таблице «Все страницы».
Canonical — где смотреть
Canonical технически не относится к meta-тегам (это <link rel="canonical">), но часто его обсуждают в одном ряду с noindex, потому что оба управляют индексацией. В SEO Crawler проверки canonical лежат в отдельном разделе «Canonical» вкладки «Техническое»: пустой canonical, canonical на чужой домен, зеркало без редиректа, относительный URL. Подробно — в Help → Ссылки и canonical. Здесь упомянем только связку с meta robots: карточка «Canonical + noindex» подсвечивает страницы, где self-canonical и noindex одновременно — это противоречивый сигнал для поисковика, и одно из двух надо убирать.
Экспорт проблем meta в XLSX
Кнопка XLSX в правом верхнем углу отчёта собирает все найденные проблемы в один Excel-файл. Для meta-тегов относятся такие листы:
| Лист в XLSX | Что внутри |
|---|---|
Missing description | URL, где meta description пустой или отсутствует |
Desc length issues | URL с коротким (<50) или длинным (>160) description + длина в символах |
Duplicate descriptions | Группы одинаковых description и URL в каждой группе |
Open Graph issues | URL без og:title, og:description, og:image, og:type, twitter:card — с признаками в отдельных колонках |
Noindex | Страницы с директивой noindex в meta robots или X-Robots-Tag |
Missing lang | Страницы без атрибута lang на <html> |
All pages | Полный дамп: URL, description, длина, og:title, og:description, og:image, meta_robots, lang, viewport |
Подробнее обо всех листах и колонках — в разделе Экспорт CSV / XLSX / PDF.
Рекомендации по длинам
SEO Crawler использует консервативные пороги, которые работают и для Google, и для Яндекса. Если ваш сайт ориентирован только на одну систему — можно сместить рамки, ориентируясь на её выдачу.
| Параметр | Google (десктоп) | Яндекс | Порог SEO Crawler |
|---|---|---|---|
| Description — обрезка в выдаче | ~155 символов | ~240 символов | 50–160 (вне диапазона = warning) |
| Description — мобильная выдача | ~120 символов | ~130 символов | — |
| og:title | 60 символов | — | наличие (длина не проверяется) |
| og:description | ~200 символов | — | наличие |
| og:image | 1200×630 px | 1200×630 px | наличие |
Важное правило: первые 120 символов description должны быть самодостаточны — они видны в мобильной выдаче, где сидит 60–70% трафика. Всё после 120 символов — бонус для десктопа.
Что делать после правок
После того как вы поправили description, OG-теги или сняли noindex с контентных страниц, запустите повторный обход в SEO Crawler и сравните счётчики проблем с предыдущим отчётом. Динамика «было 45 — стало 3» наглядно показывает прогресс и пригодится в отчёте клиенту или руководителю. Если правки делали частями (сначала description, потом OG) — запускайте обход после каждого этапа, чтобы видеть эффект изолированно.
Частые вопросы
Какой длины должен быть meta description?
SEO Crawler помечает description как «Короткое», если в нём меньше 50 символов, и как «Длинное», если больше 160. Оптимальный диапазон — 70–160 символов: Google показывает в сниппете около 155 символов на десктопе, Яндекс — до 240. Ключевую информацию ставьте в первые 120 символов — они видны даже на мобильной выдаче.
Почему Google переписывает мой description?
Google и Яндекс подставляют собственный сниппет, если ваш description не отвечает на запрос пользователя, слишком общий, дублируется на других страницах или содержит спам-конструкции. SEO Crawler показывает дубли description в карточке «Дубли» и слишком короткие/длинные — в карточках «Короткое» и «Длинное». Уникальный и конкретный description с первых 120 символов, отвечающих на запрос, минимизирует риск замены.
Что если на сайте нет og:image?
Без og:image ссылка в Telegram, VK, Facebook и LinkedIn будет выглядеть «голой» — без картинки превью, только заголовком и доменом. SEO Crawler покажет число таких страниц в карточке «Без og:image» на вкладке «Контент» → раздел «Open Graph». Рекомендуемое изображение — 1200×630 пикселей, JPG или PNG, не SVG (его плохо рендерят мессенджеры). Быстрая проверка конкретной страницы — инструмент превью Open Graph.
Нужен ли og:url, если есть canonical?
Желательно. canonical — сигнал для поисковиков, а og:url — для соцсетей и парсеров превью. В Facebook Sharing Debugger og:url используется как «исходная» ссылка для шеринга. Если og:url не задан, платформа берёт текущий URL — это обычно работает, но в случае UTM-меток или редиректов может привести к дублям превью. SEO Crawler детально по og:url в карточки не выделяет, но собирает его в таблице раздела «Open Graph / Twitter».
Как проверить meta robots на всём сайте?
Запустите полный аудит в SEO Crawler, откройте вкладку «Техническое» → раздел «Индексация». Карточка «Noindex» покажет число страниц с директивой noindex, «Canonical + noindex» — опасное сочетание, когда страница и запрещена к индексации, и ссылается на себя как canonical. Клик по карточке раскроет список URL. Та же выборка попадает в XLSX на лист Noindex.
Чем отличается meta robots и X-Robots-Tag?
meta robots — тег в HTML-<head> страницы, X-Robots-Tag — HTTP-заголовок ответа сервера. Функционально они эквивалентны (оба поддерживают noindex, nofollow, none и другие директивы), но X-Robots-Tag удобен для не-HTML ресурсов: PDF, изображений, JSON-ответов. SEO Crawler сейчас проверяет только HTML-<meta name="robots">; если вы используете X-Robots-Tag для HTML-страниц, проверьте его отдельно в инструментах вебмастера.
Индексируют ли поисковики страницу с noindex?
Нет. При наличии meta robots noindex страница не попадает в выдачу Google и Яндекса. Сканирование при этом не запрещено — краулеры заходят на страницу, читают контент и только потом видят noindex. Если страница уже была в индексе, она выпадет после ближайшего переобхода. Поэтому noindex подходит для служебных страниц (корзина, кабинет, фильтры), но опасен на контентных — их нужно индексировать.
Что с hreflang?
hreflang — отдельная тема: это не meta-тег в «шаблонном» смысле, а тег <link rel="alternate" hreflang="..."> в <head> или заголовок HTTP. SEO Crawler проверяет hreflang в разделе «Техническое» (через расширенный аудит мультиязычности). Для одной страницы быстрее использовать инструмент валидатор hreflang. Ошибки hreflang обычно связаны с неправильным кодом региона, отсутствием обратной связи x-default или несовпадением URL между версиями.
Нужен ли description на пагинации?
На ?page=2, ?page=3 и глубже — обычно нет. Если description одинаковый на всех страницах пагинации, SEO Crawler покажет их в карточке «Дубли» раздела «Описания». Правильная стратегия: уникальный description на первой странице пагинации и либо noindex, либо canonical на первую страницу — на глубоких. Это же относится к страницам фильтров каталога с однотипным контентом.
Как оптом поменять description на Bitrix/WordPress?
Сначала выгрузите проблемы из SEO Crawler в XLSX — получите листы Missing description, Desc length issues, Duplicate descriptions с URL и текущими значениями. Дальше по CMS: в WordPress используйте Yoast SEO или Rank Math для шаблонов страниц и ручной правки; в Bitrix — модуль «Поисковая оптимизация» + свойство META_DESCRIPTION в инфоблоках; в самописных CMS — выгрузите description из БД, поправьте в таблице и залейте обратно. После правок запустите повторный обход в SEO Crawler и сравните счётчики проблем с предыдущим отчётом.