Проверка контента в SEO Crawler
SEO Crawler смотрит на контент страницы с трёх сторон: сколько в ней слов содержательного текста, попадает ли она в тонкий контент (наш порог — меньше 200 слов в UI и меньше 300 слов в экспортах) и насколько глубоко она лежит от стартовой страницы обхода. Эти три проверки собраны на вкладке «Контент» отчёта и дают быстрый ответ на вопрос, какие страницы сайта поисковику нечего показывать в выдаче.
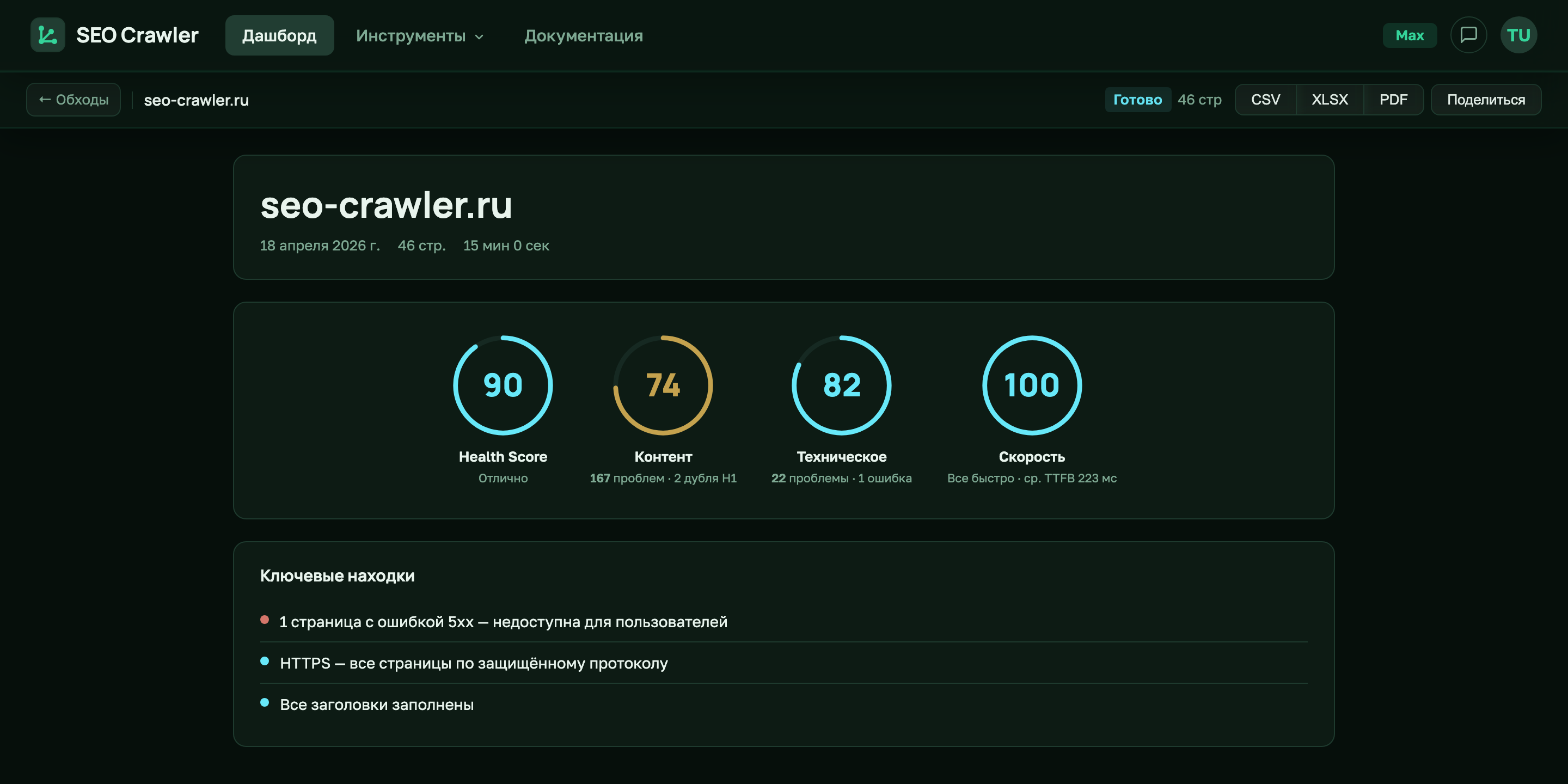
Что считает контент SEO Crawler
Краулер получает финальный HTML страницы (после редиректов, но без исполнения JavaScript) и парсит его через BeautifulSoup. Чтобы word_count отражал реальный контент, а не все подряд слова из разметки, мы вычищаем «шумные» теги перед подсчётом.
Исключаем из подсчёта полностью:
<script>— JavaScript-код;<style>— CSS-стили внутри HTML;<noscript>— fallback для браузеров без JS;<nav>— навигационные блоки (главное меню, хлебные крошки в виде nav);<header>— шапку сайта;<footer>— подвал с копирайтом и ссылками;<aside>— боковые панели, сайдбары, виджеты.
Считаем: весь видимый текст внутри <body>, который не находится в перечисленных выше тегах. То есть заголовки, параграфы, списки, ячейки таблиц, цитаты, содержимое <section>, <article> и <main> — всё это идёт в word_count. Атрибуты (alt, title, placeholder) не учитываются.
Алгоритм: достаём все текстовые узлы из body, для каждого проверяем цепочку родителей — если хоть один родитель из списка noise-тегов, узел пропускаем. Оставшиеся склеиваем через пробел и считаем len(text.split()). Получается честная оценка «содержательного» объёма: шапка и подвал, одинаковые на всех страницах сайта, word_count не раздувают.
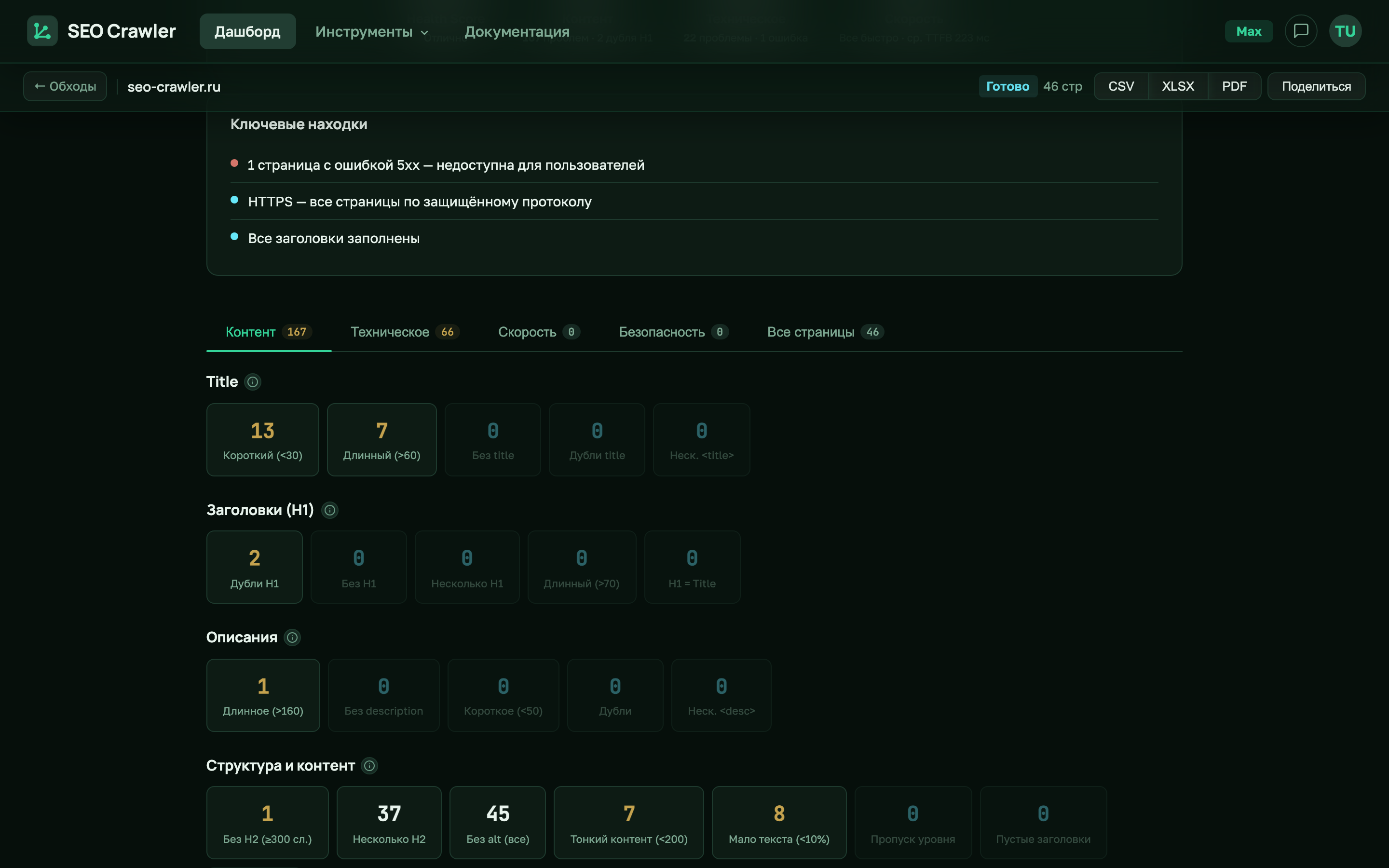
Thin content — какие пороги используем
В SEO Crawler два чуть разных порога тонкого контента для разных сценариев. В интерфейсе аудита (вкладка «Контент») карточка «Тонкий контент (<200)» показывает страницы с word_count меньше 200 — это «точка явных заглушек», URL, где контента почти нет. В экспортах XLSX и PDF порог мягче — <300 слов: там смысл не просто подсветить заглушки, а отдать разработчику и контент-менеджеру полный список кандидатов на дополнение.
| Word count | Оценка SEO Crawler | Где видно |
|---|---|---|
| < 100 слов | Критически тонкая | Вкладка «Контент» и лист Thin content в XLSX |
| 100–199 слов | Thin content в UI | Карточка «Тонкий контент (<200)» на вкладке «Контент» |
| 200–299 слов | Thin content в экспорте | Лист Thin content в XLSX и PDF, в UI уже не подсвечивается |
| 300+ слов | Нормальный объём | Везде считается «ок» |
Почему два порога. Карточка в UI нужна для быстрого ответа «есть ли на сайте явные проблемы с контентом» — и 200 слов тут пороговое значение, ниже которого страница почти гарантированно бесполезна. XLSX и PDF используют более мягкий 300-словный порог, чтобы включить в список «пограничные» страницы, которым всё ещё стоит добавить текста. Если хотите пройти по сайту и поднять каждый URL до полноценного уровня — ориентируйтесь на 300+. Если задача «закрыть самые очевидные дыры» — смотрите на карточку UI.
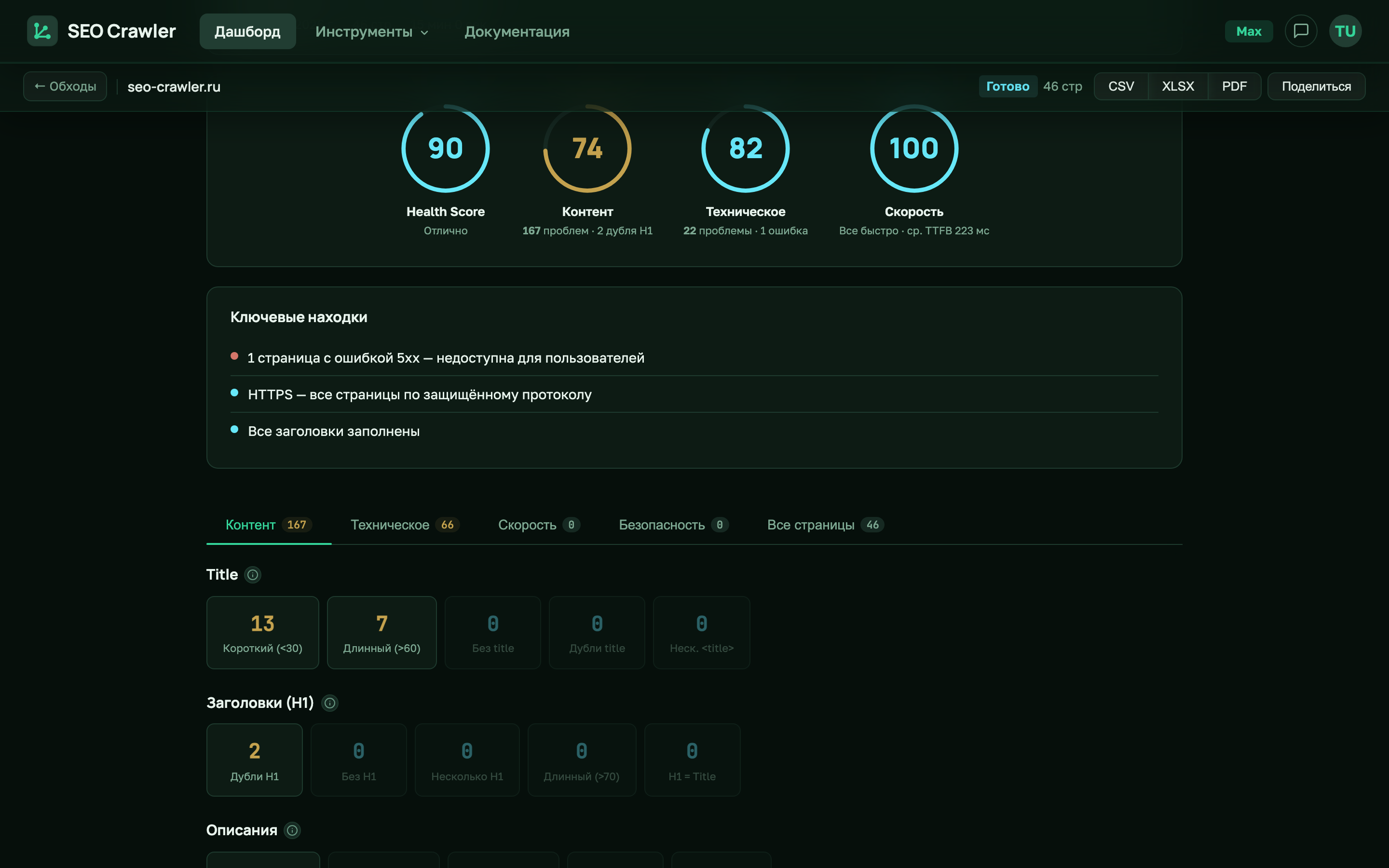
Почему тонкий контент — проблема
- Фильтры качества поисковиков. Когда доля тонких страниц на сайте большая (например, 40% и выше), весь домен получает пессимизацию — у Google это наследие Panda, сейчас часть основного алгоритма. Яндекс использует похожие фильтры качества.
- Релевантность запросу. 100 слов недостаточно, чтобы поисковик понял, по какому запросу ранжировать страницу. Она оказывается «ни о чём конкретно».
- Поведенческие факторы. Пользователь открывает страницу, видит 50 слов и уходит. Короткая сессия, высокий bounce rate, нулевая глубина просмотра — сигнал поисковику, что страница не решает задачу.
Что делать с thin content
- Дополнить. Самый очевидный путь: написать или сгенерировать описание до 300+ слов. Для карточек товаров — шаблон с подстановкой характеристик. Для категорий — вводный блок с объяснением, что здесь за товары и как их выбирать. Структуру заголовков проверьте в анализаторе заголовков.
- Объединить. Если у вас 10 тонких страниц про одно и то же (например, 10 отдельных SKU одного товара в разных цветах) — объедините в одну страницу с выбором варианта. Поисковику одна полноценная страница ценнее, чем десять заглушек.
- Закрыть от индексации. Страницы-фильтры, технические URL, «спасибо за покупку» — им не место в индексе. Поставьте
<meta name="robots" content="noindex">. Как это проверить в аудите — в статье Meta-теги и OG. - Удалить. Если страница не несёт никакой ценности и не генерирует трафик — просто удалите и настройте 301 на ближайшую релевантную категорию.
Количество слов на странице
Даже когда страница не попала в thin content, значение word_count полезно: по нему видно, какие разделы сайта «пустоваты» относительно остальных. В интерфейсе аудита мы не выводим колонку с точным числом слов — чтобы получить развёрнутую картину, выгрузите XLSX, откройте лист All pages и отсортируйте по word_count.
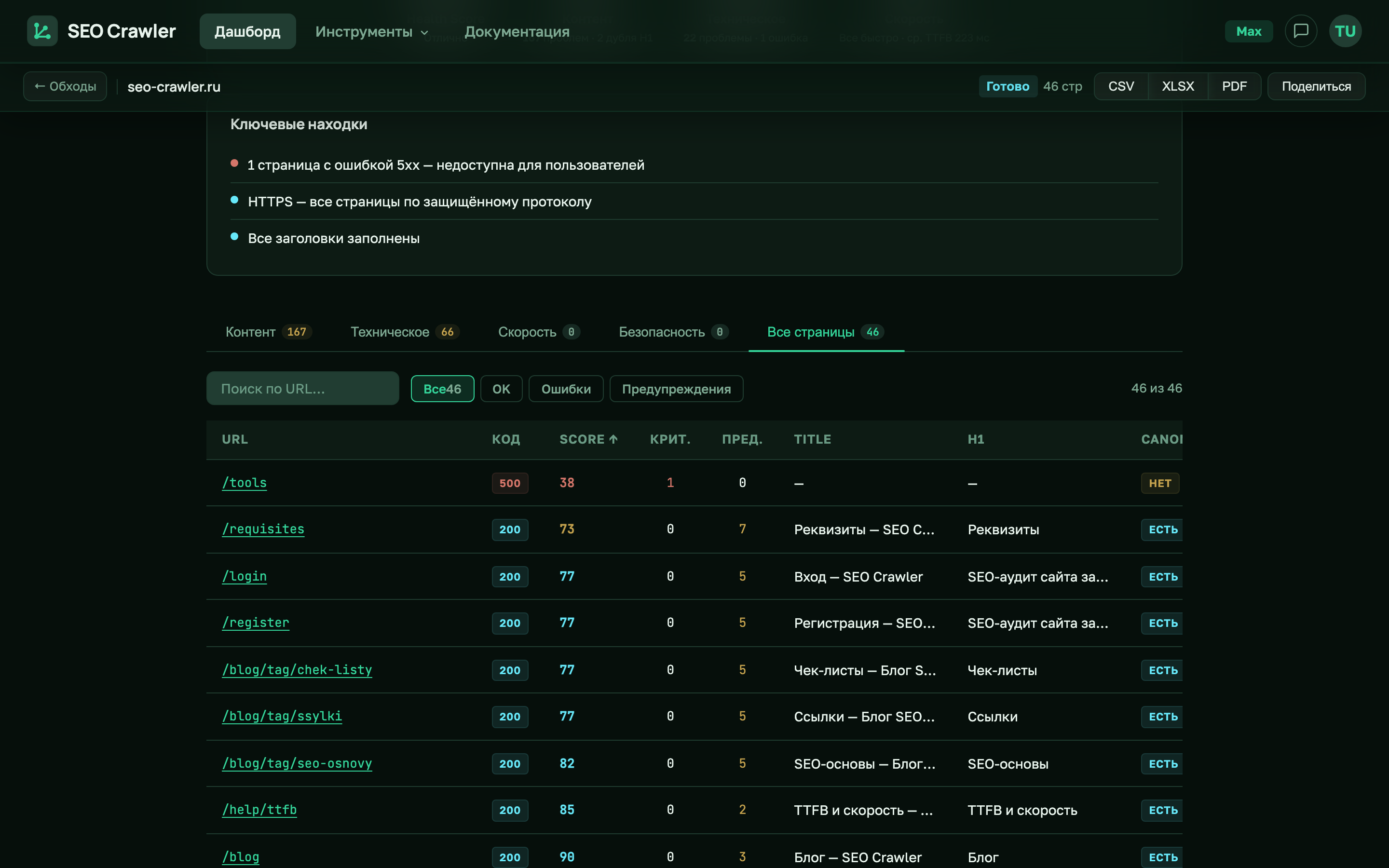
Типовые задачи, для которых удобно смотреть word_count:
- Найти «тихих» середнячков. Страницы с 300–500 словами формально не thin, но часто это ровно те URL, которым не хватает контента, чтобы конкурировать в выдаче. Усилили их — получили рост без необходимости делать новые страницы.
- Сравнить разделы. Если в разделе /articles/ среднее word_count 1200, а в /catalog/category/ — 80, это сигнал, что категории нужно доработать до уровня статей.
- Проверить результат после переписки. Запустили обход до и после правок — средний word_count по сайту должен вырасти.
Глубина страницы (click depth)
Глубина — это минимальное число кликов от стартового URL обхода до данной страницы. Краулер идёт в ширину (BFS), поэтому depth получается именно кратчайшим расстоянием в графе внутренних ссылок. Главная — глубина 0, страницы в главном меню — глубина 1, статьи внутри категории — 2–3, и так далее. В отчёте depth показывается в мини-таблице «Самые медленные страницы» (колонка Глуб.) и в полной выгрузке XLSX на листе All pages.
| Depth | Что это значит | Рекомендация |
|---|---|---|
| 0 | Стартовая страница обхода (обычно главная) | — |
| 1 | Один клик — главное меню, хедер, главные CTA | Здесь должны быть ключевые разделы |
| 2 | Два клика — категории, разделы блога | Хороший уровень для важных страниц |
| 3 | Три клика — статьи, карточки товаров | Всё ещё ок, но следите за объёмом |
| 4 | Четыре клика — глубокие страницы | Важные URL сюда попадать не должны |
| 5+ | Пять и больше — хуже индексируются | Добавьте ссылки с верхних уровней или пересмотрите структуру |
depth — отсортируйте по убыванию и увидите самые глубокие URL сайта.Почему глубина важна
- Crawl budget. У поисковиков ограниченный бюджет на обход каждого сайта. Страницы глубже 4 уровня обходятся реже или не обходятся совсем — особенно на больших каталогах. Чем быстрее ботам добраться до URL, тем выше шанс его проиндексировать и переиндексировать после обновлений.
- Передача PageRank. С каждым уровнем вложенности внутренний вес «разбавляется» — он распределяется между всеми исходящими ссылками страницы. К пятому уровню ссылочный вес, доставшийся странице, близок к нулю, если только на неё не ссылаются извне структуры (например, из статьи блога на URL категории).
- Пользовательский опыт. Если до страницы нужно 5+ кликов, пользователь туда физически не доберётся. Ни поведенческие метрики, ни конверсия такой URL не спасут.
Дубли текста — это мы не проверяем
Честный ответ: на этом шаге SEO Crawler не сравнивает тексты страниц между собой. Чтобы найти реальные дубли n-gram-ами или через shingle-хеши, нужен отдельный индекс всего сайта и специализированный алгоритм — это задача инструментов вроде Siteliner, Copyscape или text.ru.
Что мы делаем и что даёт косвенный сигнал по дублям контента:
- Дубли title. Если десять URL имеют один и тот же title «Купить диван» — с большой вероятностью описания там тоже идентичные. Проверяется на вкладке «Контент» → карточка «Дубли title».
- Дубли H1. То же самое — одинаковые H1 почти всегда означают, что страницы получены из одного шаблона и отличаются только URL.
- Canonical. Страницы с одинаковым canonical-ом поисковик склеит, и это ок — подробнее в справке про ссылки и canonical.
Если нужно именно сравнить тексты — выгрузите XLSX с полным списком URL, пройдитесь внешним инструментом на shingle-анализ и уже по его результатам возвращайтесь к структуре.
Экспорт контентных проблем в XLSX
Кнопка XLSX в правом верхнем углу отчёта собирает все найденные проблемы в Excel-файл. По теме контента полезны такие листы:
| Лист в XLSX | Что внутри |
|---|---|
Thin content | URL со значением word_count меньше 300, отсортированные по возрастанию количества слов |
All pages | Все URL с колонками url, word_count, depth, title, h1, status_code и остальными метриками |
Duplicate titles | Группы одинаковых title — полезно как прокси для поиска дубликатов описаний |
Практика: откройте All pages в Excel, отсортируйте по word_count по возрастанию, фильтром оставьте status_code = 200 — получите ранжированный список кандидатов на дополнение. Вторым фильтром поставьте depth > 3 — и сразу увидите самые «пыльные углы» сайта, где тонкий контент комбинируется с высокой глубиной. Такие URL имеет смысл либо серьёзно дорабатывать, либо закрывать noindex, либо удалять.
Подробнее обо всех листах и форматах — в разделе Экспорт CSV / XLSX / PDF.
Что делать после правок
После того как вы дописали описания, добавили вводные блоки в категории и переструктурировали меню — запустите повторный обход в SEO Crawler и сравните цифры с предыдущим отчётом. Смотрите три показателя:
- Число страниц в «Thin content». Должно уменьшиться. Если не уменьшилось — значит, добавленный текст не попал в word_count (вероятно, подгружается JS — см. callout выше).
- Средний word_count по сайту. Считается из
All pages: сумма word_count делённая на число URL со статусом 200. Средний объём должен вырасти. - Максимальная глубина. Если реструктурировали меню — максимальный depth должен уменьшиться. Идеально: все важные разделы на глубине <= 3.
Если подключён тариф Pro, сравнение двух обходов делает отдельный инструмент — он покажет дельту по каждому URL и сам подсветит страницы, где word_count вырос или упал. Удобно для отчётов клиенту и себе на будущее.
Частые вопросы
Какой минимум слов на странице должен быть по версии SEO Crawler?
У нас два слегка разных порога. В UI аудита карточка «Тонкий контент» загорается, когда word_count меньше 200 слов — это условие «явной заглушки». В экспортах XLSX и PDF порог мягче: на лист Thin content уходят все страницы с word_count меньше 300 — это кандидаты на дополнение. 300 слов считается «безопасной нормой» в большинстве SEO-гайдов. Оба порога — ориентир, а не жёсткое правило: для страницы контактов 50 слов нормально, а для статьи блога и 500 бывает мало.
Thin content действительно убивает SEO?
Не столько убивает одна страница, сколько весь сайт, если тонких страниц много. У Google это часть основного алгоритма (бывший Panda), у Яндекса — фильтры качества. Чем больше доля тонких страниц к общему числу URL в индексе, тем ниже общий уровень доверия к домену. Одна страница контактов с 50 словами сайту не повредит. 5000 тегов каталога по 20 слов каждый — повредят.
Учитывается ли текст в alt и title при подсчёте слов?
Нет. SEO Crawler считает только видимый текст внутри <body>, который не лежит в служебных тегах (script, style, noscript, nav, header, footer, aside). Атрибуты alt у картинок, title у ссылок и текст внутри input не попадают в word_count. Это сделано намеренно: поисковик учитывает alt как сигнал для картинки, но не как контент страницы.
Как исправить страницы-заглушки категорий в интернет-магазине?
Добавьте вводный текст перед листингом товаров — 200–400 слов с описанием, чем именно полезна категория, какие товары в неё входят, как их выбирать. Можно вынести в складку «Подробнее» под первым экраном, чтобы не мешать навигации. Также добавьте FAQ-блок в подвале категории — 5–7 типовых вопросов закрывают дополнительно 150–300 слов и отрабатывают голосовой поиск.
Считаем ли мы FAQ-блоки как контент?
Да, если они отдаются в HTML. SEO Crawler парсит финальный HTML, который пришёл с сервера, и всё, что лежит в <body> вне nav/header/footer/aside, идёт в word_count. Accordion-FAQ, развёрнутый через <details>/<summary>, тоже считается, потому что текст внутри summary и div[role=region] находится в DOM. А вот FAQ, подгружаемый JavaScript-ом после загрузки страницы, мы не увидим — краулер не рендерит JS.
Глубина больше 5 уровней — это критично?
Да, для индексации и crawl-budget — критично. SEO Crawler считает глубину как минимальное число кликов от стартовой страницы обхода. Страницы глубиной 4+ обходятся поисковиками реже, 6+ часто не попадают в индекс вовсе. В отчёте вы увидите распределение по уровням в таблице «Все страницы» — сортируйте по колонке depth и проверяйте, что важных URL на глубине 4+ нет.
Как добавить контент на карточки товаров, не раздувая каждую страницу вручную?
Три типовых приёма. Первое — шаблонные описания с подстановкой атрибутов товара: 100–150 слов генерируются из параметров (материал, габариты, страна). Второе — блок отзывов из реальных покупок: они считаются контентом и уникальны по определению. Третье — раздел «С этим товаром покупают» с описанием каждой позиции в 1–2 предложения. Совокупно это даёт 300+ слов уникального текста без ручной работы по каждому SKU.
Что делать с дублями описаний товаров в e-commerce?
SEO Crawler не ищет дубли текстов между страницами напрямую — это задача специализированных инструментов по сравнению n-gram. Но мы показываем дубли title и H1 на вкладке «Контент»: если два URL имеют одинаковые title и одинаково тонкий word_count, это почти гарантированно дубли описаний. Исправление — переписать описания вручную или через шаблон с подстановкой параметров товара.
Проверяет ли SEO Crawler уникальность контента между страницами?
Нет, уникальность n-gram мы не сравниваем. Это требует отдельного сервиса с индексом всех страниц сайта и алгоритмом shingle-хешей. SEO Crawler на этом шаге отрабатывает косвенные сигналы — дубли title и H1, тонкий контент, подозрительно одинаковый word_count у большой группы страниц. Если нужна именно уникальность текста, используйте text.ru, content-watch.ru или платные инструменты типа Siteliner.
Игнорируется ли текст, скрытый в модалках и табах?
Смотря как он реализован. Если содержимое модалки лежит в HTML и просто скрыто через CSS (display:none или класс .hidden), мы его посчитаем — оно в DOM. Если модалка подгружается по клику через fetch, мы его не увидим, потому что не исполняем JavaScript. Рекомендуем важный контент держать в HTML сразу — так его видят и поисковики, и наш краулер. Тексту в модалках поисковик даёт меньший вес, но индексирует.