Экспорт отчётов в SEO Crawler
После завершения обхода все данные можно выгрузить из SEO Crawler в трёх форматах: CSV — простая таблица всех страниц, XLSX — многолистовая Excel-книга с разбивкой проблем по 18 категориям плюс общим листом, и PDF — готовый отчёт с обложкой и резюме для передачи клиенту или руководителю. Файлы создаются на лету из текущего состояния обхода и не хранятся на сервере — каждый экспорт формируется заново.

Формат CSV — для интеграций и свободной обработки
CSV — простой текстовый формат в одну таблицу: 23 колонки, одна строка на страницу. Подходит, когда вы хотите подключить данные аудита к внешнему инструменту: выгрузить в Google Sheets для совместной работы, отдать аналитику в Python/R, залить в Superset или Metabase, сравнить с выгрузкой из Search Console или положить рядом с ключами из Key Collector.
Кодировка. Файл отдаётся в UTF-8 с BOM (\ufeff в самом начале) — это «подсказка» для Excel, которая заставляет его правильно прочитать кириллицу без ручной настройки. Content-Type в ответе — text/csv; charset=utf-8-sig. В современных версиях Excel (2016+), Google Sheets, Numbers и LibreOffice Calc такой файл открывается двойным кликом.
Разделитель. Запятая — стандартный для CSV. Строковые поля, внутри которых встречается запятая или перенос строки, автоматически оборачиваются в двойные кавычки. Значения с формулами (начинающиеся с =, +, -, @) защищены от formula injection — SEO Crawler добавляет к ним префикс, чтобы Excel не выполнил выражение как формулу.
Что в колонках. Порядок колонок фиксирован и совпадает с порядком HEADERS в коде экспорта:
| Колонка | Описание |
|---|---|
url | Полный URL страницы — первичный ключ строки |
status_code | Код HTTP финального ответа (200, 301, 404, 5xx) |
title | Текст тега <title> |
title_length | Длина title в символах |
meta_description | Текст meta description |
description_length | Длина description в символах |
h1 | Первый H1 на странице |
h1_count | Сколько H1 найдено (ожидается 1) |
lang | Атрибут lang в <html> |
canonical | Значение <link rel="canonical"> |
meta_robots | Директивы robots из meta или X-Robots-Tag |
og_title / og_description / og_image | Open Graph для превью в соцсетях |
images_without_alt | Сколько <img> без alt на странице |
internal_links_count / external_links_count | Количество ссылок каждого типа |
word_count | Слов в видимом тексте |
response_time_ms | TTFB в миллисекундах |
redirect_count / has_redirect_loop / redirect_chain | Цепочка редиректов и признак петли |
page_size_bytes | Размер HTML в байтах |
depth | Кратчайшее число кликов от стартового URL |
error | Текст ошибки, если страницу не удалось загрузить |
Скачивание CSV работает в стриминговом режиме: сервер отдаёт файл построчно, не загружая весь список в память. Благодаря этому экспорт обхода на 5 000 страниц (максимум для тарифа Max) не создаёт пиковой нагрузки и начинает скачиваться сразу после нажатия кнопки.
Формат XLSX — многолистовой отчёт с разбивкой по типам проблем
XLSX — самый богатый формат. SEO Crawler формирует Excel-книгу из 19 листов: один лист All pages со всеми обойдёнными URL и ещё 18 тематических листов, на каждом из которых лежат страницы с конкретной проблемой. Такая раскладка экономит время: чтобы найти все 404, не нужно фильтровать общий список — откройте лист 4xx errors и получите готовую выборку.
Файл создаётся библиотекой openpyxl в режиме write_only — это экономит память, так что даже обход на 5 000 страниц собирается без пиков ОЗУ. Результат сохраняется во временный файл и сразу отдаётся в ответе; после ответа временный файл удаляется.
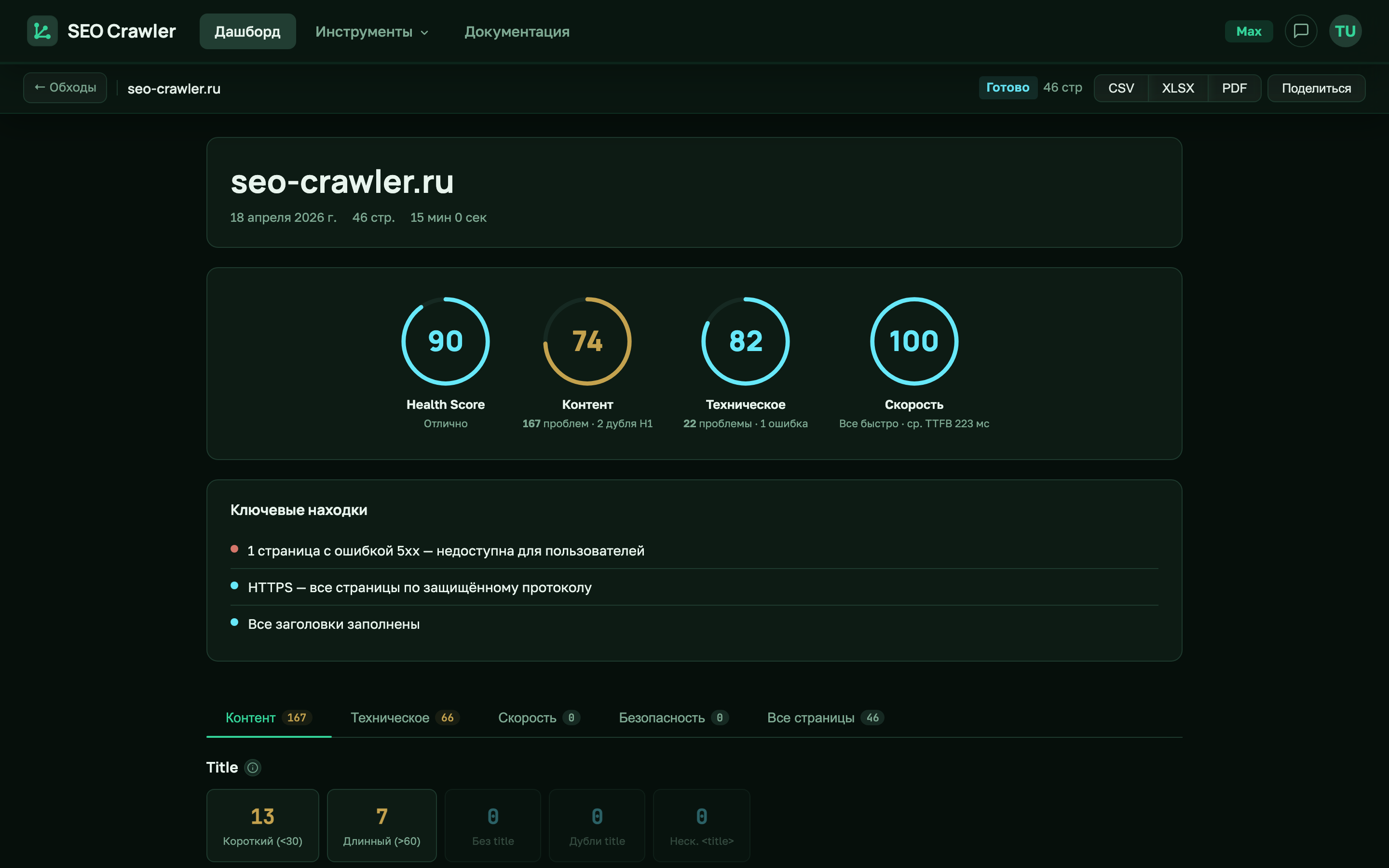
Все 19 листов XLSX
Имена листов и их содержимое зафиксированы в коде — вот полная таблица:
| Лист | Что содержит | Как собирается |
|---|---|---|
All pages | Все страницы обхода — те же 23 колонки, что и в CSV | Стриминг по всем URL |
4xx errors | Страницы с кодом ответа 400–499: 404 Not Found, 403 Forbidden, 410 Gone | 400 ≤ status_code < 500 |
5xx errors | Серверные ошибки: 500, 502, 503, 504 | status_code ≥ 500 |
Unreachable | URL, до которых краулер не смог достучаться: таймаут, DNS, SSL-ошибка | Поле error заполнено |
Missing title | Страницы без тега <title> или с пустым title | title пустой |
Missing description | Страницы без meta description | meta_description пустое |
Missing h1 | Страницы без <h1> | h1 пустой |
Missing canonical | Страницы без <link rel="canonical"> | canonical пустой |
Imgs without alt | Страницы с изображениями без атрибута alt | images_without_alt > 0 |
Duplicate titles | Группы страниц с одинаковым title | Counter по всем title → те, что встречаются ≥ 2 раз |
Duplicate descriptions | Страницы с одинаковым meta description | Counter по описаниям |
Thin content | Страницы с менее чем 300 словами в видимом тексте | word_count < 300 |
Title length issues | Слишком короткие (<30) или слишком длинные (>60) title | Подробнее — в Title и H1 |
Desc length issues | Description короче 70 или длиннее 160 символов | description_length < 70 или > 160 |
Noindex | Страницы с meta robots noindex — не попадут в поиск | В meta_robots есть «noindex» |
Redirects | Страницы, которые отдали редирект перед финальным ответом | redirect_count > 0 |
Slow TTFB >800ms | Медленные страницы: время до первого байта больше 800 мс | response_time_ms > 800 |
Multiple H1 | Страницы с двумя и более <h1> | h1_count > 1 |
Missing lang | Страницы без атрибута lang в <html> | lang пустой |
All pages. Это удобно, если вы потом сводите данные VLOOKUP-ом или PivotTable — колонки везде в одном порядке.Детали о проблемах title и H1 — в статье Проверка Title и H1 в SEO Crawler. О структуре ссылок и canonical — Ссылки и canonical. О TTFB и скорости — Скорость и редиректы.
Формат PDF — для клиента и руководителя
PDF — единственный формат, который можно отдать заказчику без пояснений. Аккуратный A4-документ с обложкой, оглавлением и сквозным оформлением, собранный из фирменного HTML-шаблона. Шрифт — Inter, фирменная типографика SEO Crawler.
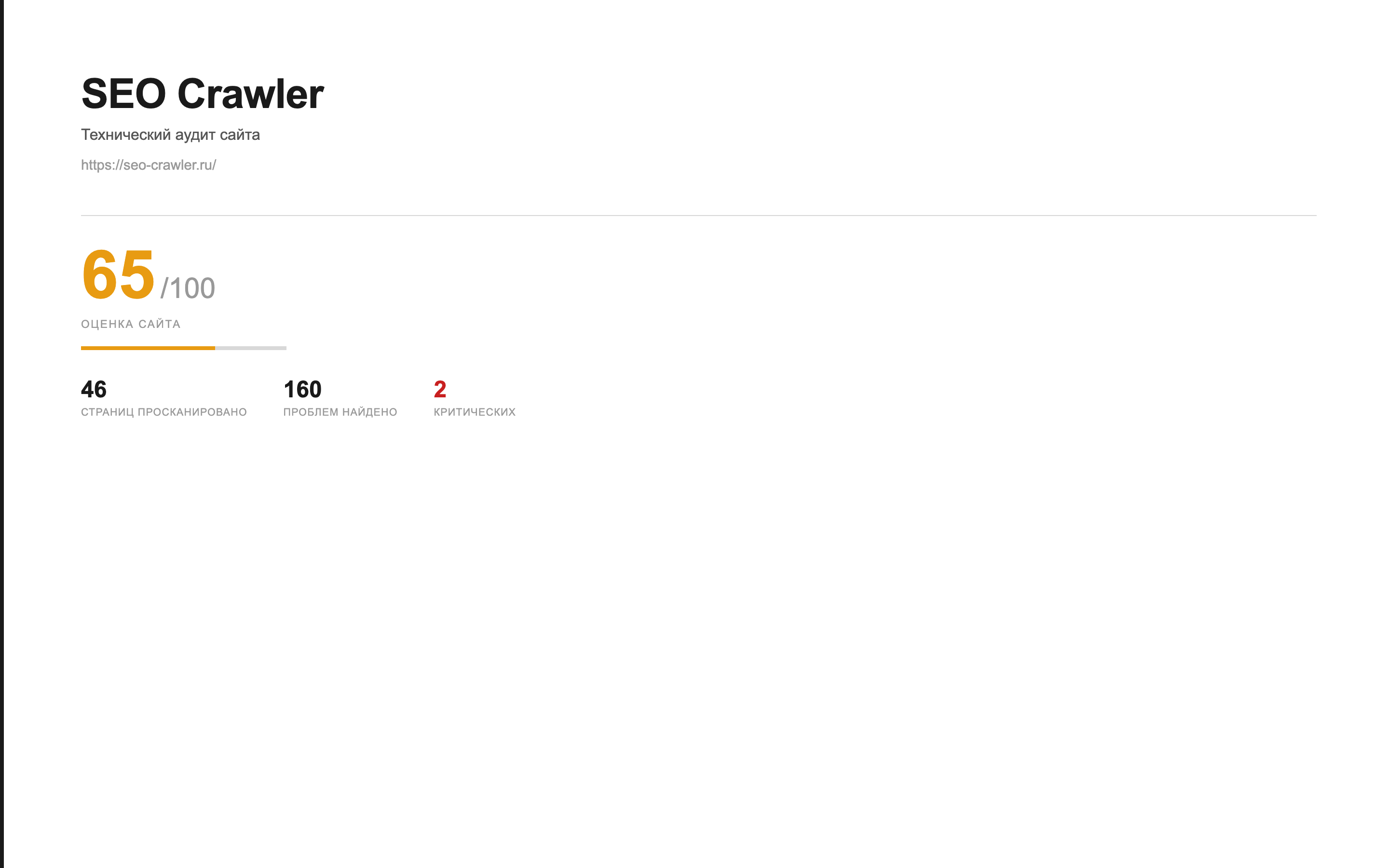
Структура PDF — 9 логических разделов с собственными главами в оглавлении:
- Обложка — бренд, URL, дата, Health Score из 100, число страниц и критических проблем. На white-label — логотип агентства и «Подготовлено для клиента».
- Содержание — нумерованный список разделов с точками-заполнителями.
- Параметры сканирования — дата обхода, количество URL, настройки краулера (скорость, глубина, User-Agent).
- Резюме — верхнеуровневая выжимка: ключевые метрики и главные выводы по сайту.
- Что нужно исправить — приоритизированный план действий (показывается, если найдены проблемы).
- Обзор аудита — сводка по всем категориям проверок с числом ошибок и предупреждений.
- Проверка домена — SSL-сертификат, robots.txt, sitemap, редиректы с www/без www — если включена.
- Чеклист проверок — список всех проведённых проверок с результатом pass/fail.
- Найденные проблемы — таблицы страниц с ошибками 4xx/5xx, без title/description/H1, топ медленных по TTFB.
- Итоги и следующие шаги — рекомендации и приоритетные задачи (подраздел «Приоритетные задачи»).
- Приложение «Без замечаний» — список пройденных проверок, если их много.
Итоговый размер PDF для обхода на 500 страниц — от 200 КБ до 1–2 МБ в зависимости от числа проблемных страниц (больше проблем → больше таблиц). Файл открывается в любом PDF-ридере — Acrobat, Preview на macOS, Edge, Foxit — и распечатывается без потери оформления.
Какой формат когда выбирать
Кратко — простая матрица сценария и оптимального формата:
| Сценарий | Формат | Почему |
|---|---|---|
| Передать отчёт клиенту или руководителю | Обложка, резюме, Health Score — понятно без пояснений | |
| Отдать задачу разработчику или контент-менеджеру | XLSX | Каждая проверка на отдельном листе — легко фильтровать и сортировать |
| Загрузить в Google Sheets для совместной работы | XLSX | Все 19 листов переносятся без потерь |
| Подключить к внешнему инструменту (BI, Python, R) | CSV | Минимум оверхеда, читается любой библиотекой |
| Сохранить исторический снапшот обхода | PDF + XLSX | PDF — для визуального архива, XLSX — для будущего diff-а |
| Быстро прислать ссылку заказчику | Поделиться PDF | Кнопка «Поделиться» даёт публичный URL без регистрации |
| Провести свой анализ данных | CSV | Стриминг, работает для самых больших обходов |
Права доступа и тарифы
Доступ к форматам экспорта зависит от тарифа. Проверить свой тариф можно в шапке — бейдж рядом с аватаром, либо в настройках.
| Формат | Free | Pro | Max | Триал (7 дней) |
|---|---|---|---|---|
| CSV | Да | Да | Да | Да |
| XLSX (19 листов) | Да | Да | Да | Да |
| — | Да | Да | Да | |
| White-label PDF | — | — | Да | — |
| Кнопка «Поделиться» (публичный URL) | — | Да | Да | Да |
Подробнее о тарифах — в статье Free, Pro и Max или на странице тарифов. White-label PDF (логотип агентства, имя клиента в поле «Подготовлено для») доступен только на Max и настраивается в разделе «Настройки» → «Брендинг PDF».
Автоматизация экспорта через расписания
Если вы следите за сайтом на длинной дистанции, ручной экспорт каждый раз — лишняя рутина. SEO Crawler умеет запускать обходы по расписанию и уведомлять по email о завершении — в письме есть прямая ссылка на отчёт, откуда один клик до любого из трёх форматов экспорта.
Расписания доступны на Pro (ежемесячно) и Max (ежедневно, еженедельно, ежемесячно). Как запустить — в статье Как работает краулер, раздел «Начало обхода». После завершения планового обхода scheduler-воркер отправляет письмо с темой «Обход сайта завершён» и ссылкой на отчёт — оттуда вы или ваш клиент жмёте CSV/XLSX/PDF в один клик.
Совместимость с Excel, Google Sheets и LibreOffice
Все три формата тестируются на популярных ридерах:
- Microsoft Excel 2016+ — открывает CSV и XLSX без настроек. BOM в CSV обеспечивает корректную кириллицу.
- Google Sheets — загрузите XLSX через «Файл → Импорт» и выберите «Заменить таблицу» или «Новый лист». Все 19 листов переносятся.
- LibreOffice Calc и OnlyOffice — читают и XLSX, и CSV без нюансов. При импорте CSV выберите кодировку UTF-8.
- Apple Numbers — открывает XLSX, но некоторые сложные форматы ячеек упрощает. Для сложной работы лучше Excel или Sheets.
- PDF — любой современный ридер: Acrobat, Preview, Edge, Chrome, Foxit, Adobe Reader.
Старые версии Excel (2010 и ранее) могут не справиться с UTF-8 с BOM — в этом случае используйте XLSX или импортируйте CSV через «Данные → Из текста» с явным указанием кодировки 65001 (UTF-8). Но в 2026 году доля таких клиентов — считаные проценты.
Размер файлов: чего ожидать
Ориентировочные размеры для обходов разного масштаба:
| Страниц в обходе | CSV | XLSX | |
|---|---|---|---|
| 50 (Free) | ~20–50 КБ | ~40–80 КБ | ~150–300 КБ |
| 500 (Pro) | ~200–500 КБ | ~300–700 КБ | ~250–600 КБ |
| 1 000 | ~400 КБ – 1 МБ | ~700 КБ – 1,5 МБ | ~350–900 КБ |
| 5 000 (Max) | ~2–5 МБ | ~3–10 МБ | ~500 КБ – 2 МБ |
Реальный размер зависит от длины title, description и URL вашего сайта — а главное, от того, сколько найдено проблем: в XLSX каждая проблема увеличивает соответствующий лист, а в PDF — увеличивает раздел «Найденные проблемы». PDF весит меньше XLSX, потому что в него попадают только агрегаты и топы (а не все 5 000 строк).
Экспорт из шапки задачи и из таблицы «Задачи»
Те же три кнопки доступны и на /dashboard — в каждой строке таблицы «Задачи» справа есть action-группа с CSV, XLSX и PDF. Это удобно, когда вы ведёте несколько сайтов и хотите выгрузить отчёт, не открывая каждый по отдельности.
Частые вопросы
Какой формат экспорта лучше отправлять клиенту?
PDF — он самый наглядный: обложка с Health Score, резюме, раздел «Что нужно исправить» и таблицы проблем. Файл A4 в альбомной ориентации, его удобно распечатать или переслать без дополнительных инструкций. PDF доступен на тарифах Pro и Max, а также во время триала.
Можно ли кастомизировать PDF под свой бренд?
Да, но только на тарифе Max — там доступен white-label PDF: логотип агентства, название бренда и имя клиента в поле «Подготовлено для». На Pro PDF выходит с брендингом SEO Crawler. Все настройки задаются в разделе «Настройки» → «Брендинг PDF».
Почему CSV открывается в Excel с кракозябрами?
SEO Crawler выдаёт CSV в UTF-8 с BOM — современные версии Excel (2016+) и LibreOffice читают его без проблем. Если в старом Excel всё равно ломается кодировка, откройте файл через «Данные → Получить данные → Из текста/CSV», выберите кодировку UTF-8 и разделитель «запятая».
Откуда берутся данные для экспорта?
Все три формата формируются из одной таблицы crawl_results — страниц, обойдённых краулером. В CSV и на листе All pages XLSX попадают все 23 поля: URL, статус, title, H1, canonical, robots, OG, TTFB, ссылки, изображения, word_count, глубина и ошибки. В PDF берутся агрегаты и топы проблемных страниц.
Открывается ли XLSX в Google Sheets и LibreOffice?
Да. Файл формируется библиотекой openpyxl в формате Office Open XML (.xlsx) — он совместим с Excel 2007+, Google Sheets, LibreOffice Calc, Apple Numbers и онлайн-редакторами вроде OnlyOffice. При загрузке в Google Sheets все 19 листов переносятся без потерь.
Сколько хранится файл экспорта на сервере?
Нигде не хранится. Все три формата генерируются на лету при нажатии кнопки: CSV стримится частями, XLSX и PDF создаются во временном файле и отдаются в ответ, после чего временный файл удаляется. Если нужно сохранить отчёт — скачайте его себе на компьютер.
Можно ли выгрузить только битые ссылки или только проблемы title?
В XLSX проблемы уже разложены по листам: 4xx errors, 5xx errors, Missing title, Title length issues, Duplicate titles и так далее — всего 19 листов. Просто откройте нужный лист, выделите диапазон и скопируйте в свою таблицу. Отдельной «селективной» выгрузки одной проверки нет — но изолированные листы закрывают эту задачу.
Доступен ли экспорт на бесплатном тарифе?
CSV — да, на всех тарифах, включая Free. XLSX — также доступен на Free и выгружает все 19 листов. PDF — только на Pro и Max и на активном триале, потому что генерация PDF нагрузочная. На Free кнопка PDF открывает окно с предложением апгрейда.
Как отправить готовый PDF заказчику?
Самый быстрый способ — нажать кнопку «Поделиться» рядом с PDF на странице аудита: получите публичную ссылку, которую можно отправить по email или в мессенджере без регистрации на стороне клиента. Либо скачайте PDF, приложите к письму и отправьте вручную — файл весит 200–600 КБ.
Что содержит лист «All pages» в XLSX-отчёте?
Все страницы, обойдённые краулером, с 23 колонками: url, status_code, title, title_length, meta_description, description_length, h1, h1_count, lang, canonical, meta_robots, og_title, images_without_alt, internal_links_count, external_links_count, word_count, response_time_ms, redirect_count, has_redirect_loop, redirect_chain, page_size_bytes, depth, error.